Wir möchten nun nachvollziehen, wie die nhanes-Tabelle, mit der wir bisher immer angefangen haben, zustande gekommen ist.
Ich habe sie aus zwei Tabellen zusammengesetzt, die ich beide von der NHANES-Webseite (hier) herunter geladen habe: DEMO_J.XPT (demographics) und BMX_J.XPT (body measurements). Das “J” steht für den Durchgang (2017/18).
Beide Dateien liegen im XPT-Format vor, dem Export-Format von SAS (einem kommeriziellen Statistik-Paket, dass ähnliche Funktionalität wie R bereits stellt). Tidyverse hat eine Sammlung von Import-Filtern, um Daten von Fremd-Programmen zu laden, das Paket “haven”. Darin finden wir die Funktion read_xpt:
Die Tabelle enthält 46 Spalten, die mit merkwürdigen Abkürzungen versehen sind. Deren Bedeutung entnehmen wir dem Codebuch für DEMO_J auf der Webseite.
Mit dem Tidyverse-Verb select können wir Spalten auswählen. Die restlichen Spalten werden verworfen:
Die Funktion left_join braucht min. drei Argumente, zwei Tabellen (genannt linke und rechte Tabelle), sowie einen sog. “Schlüssel”.
Die Grundregel für left_join lautet:
An jede Zeile der linken Tabelle (demo_j_selected) wird die passende Zeile aus der rechten Tabelle (gender_codes) angehängt werden.
Die “passende Zeile” erkennt man daran, dass dort der Wert der Schlüssel-Spalten (key columns) übereinstimmt.
Bei unserem Beispiel gilt also:
An jede Zeile der Tabelle demo_j_selected wird die passende Zeile aus der Tabelle gender_codes angehängt werden.
Die “passende Zeile” erkennt man daran, dass dort der Wert in der Spalte gender_code der linken Tabelle mit dem Wert in der SPalte code der rechten Tabelle übereinstimmt, weil unser Schlüssel-Argument c( "gender_code" = "code" ) lautet.
Im Ergebnis findet man nun alle 4 Spalten aus der linken Tabelle und fast alle Spalten aus der rechten Tabelle. Lediglich die Schlüsselspalte der rechten Tabelle (gender_codes$code) wurde weg gelassen. – Sie wird nicht mehr gebraucht, da sie ja dieselben Werte enthält wie demo_j_selected$gender_code.
Es gibt zwei Sonderregeln für den Fall, dass nicht genau eine Zeile passt
Wenn in der rechten Tabelle keine passende Zeile gefunden werden kann, wird NA in die hinzugefügten Felder gesetzt.
Wenn in der rechten Tabelle mehrere passende Zeilen gefunden werden, werden mehrere Kopien der Zeile aus der linken Tabelle angefertigt und jeder jeweils eine der gefundenen Zeilen aus der rechten Tabelle angefügt.
Der erste Fall könnte auftreten, falls ein Code in unserem Codebuch fehlt. Dann ist ein NA aber genau, was wir wollen, denn die Information, was der Code bedeutet, fehlt ja.
Der zweite Fall kann für Chaos sorgen, der er Probanden “verdoppeln” könnte. Daher ist wichtig, dass in unserer (rechten) Code-Tabelle kein Code zweimal auftaucht. Als Vorsichtsmaßnahme soltlen wir daher bei unserem left_join das Zusatz-Argument relationship = "many-to-one" angeben, dass eine Fehlermeldung bewirkt, falls es mehr als eine passende rechte Zeile gibt.
Für das Schlüssel-Argument ist noch zu sagen:
Die Anführunsgzeichen um die Spaltennamen dürfen nicht fehlen.
Oft hat man mehrere Schlüsselspalten, die alle in beiden Tabellen übereinstimmen sollen. Dann gibt man sie einfach an als c( "left_key_1"="right_key_1", "left_key_2"="right_key_2" ).
Wenn die Schlüsselspalte in beiden Tabellen gleicht heisst, kann man abgekürzt "key" schreiben statt c("key"="key").
Außerdem:
Wenn ein Spaltennamen in beiden Tabellen vorkommt, aber nicht Schlüssel ist, werden beide Spalten übernommen. Zur Unterscheidung werden den Spaltennamen die Suffixes .x und .y angehängt.
Aufgabe
Schreiben Sie aus dem Codebuch die Code-Tabelle für die Ethnien (RIDRETH3) ab. Verwenden Sie left_join, um die Ethnie-Codes durch aussagekräftige Bezeichnungen zu ersetzen.
# A tibble: 9,254 × 4
subjectId age gender ethnicity
<dbl> <dbl> <chr> <chr>
1 93703 2 female NH Asian
2 93704 2 male NH White
3 93705 66 female NH Black
4 93706 18 male NH Asian
5 93707 13 male other/multi
6 93708 66 female NH Asian
7 93709 75 female NH Black
8 93710 0 female NH White
9 93711 56 male NH Asian
10 93712 18 male Mexican
# ℹ 9,244 more rows
Hier haben wir das Verb select in einer alternativen Form verwendet: Wenn man einem Spaltennamen ein Minus voranstellt, wird diese Spalte entfernt und alle anderen Spalten werden beibehalten. Damit haben wir die beiden Code-Spalten entfernt, da wir sie nun nicht mehr brauchen.
Die BMX-Tabelle
Nun laden wir noch die Body-Measures-Tabelle. Sie finden die Datei BMX_J.XPT auf der NHANES-Webseite, Bereich “Survey Data and Documentation”, Durchgang J (2017/18), Abschnitt “Examination Data”.
read_xpt( "Downloads/BMX_J.XPT" )
# A tibble: 8,704 × 21
SEQN BMDSTATS BMXWT BMIWT BMXRECUM BMIRECUM BMXHEAD BMIHEAD BMXHT BMIHT
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 93703 1 13.7 3 89.6 NA NA NA 88.6 NA
2 93704 1 13.9 NA 95 NA NA NA 94.2 NA
3 93705 1 79.5 NA NA NA NA NA 158. NA
4 93706 1 66.3 NA NA NA NA NA 176. NA
5 93707 1 45.4 NA NA NA NA NA 158. NA
6 93708 1 53.5 NA NA NA NA NA 150. NA
7 93709 1 88.8 NA NA NA NA NA 151. NA
8 93710 1 10.2 NA 74.3 NA NA NA NA NA
9 93711 1 62.1 NA NA NA NA NA 171. NA
10 93712 1 58.9 NA NA NA NA NA 173. NA
# ℹ 8,694 more rows
# ℹ 11 more variables: BMXBMI <dbl>, BMXLEG <dbl>, BMILEG <dbl>, BMXARML <dbl>,
# BMIARML <dbl>, BMXARMC <dbl>, BMIARMC <dbl>, BMXWAIST <dbl>,
# BMIWAIST <dbl>, BMXHIP <dbl>, BMIHIP <dbl>
Aufgabe
Selektieren Sie die Spalten mit der Probanden-ID, dem Körpergewicht in kg und der Körpergröße in cm. Benennen Sie die Spalten um zu “subjectId”, “weight” und “height”.
Fügen Sie diese Tabelle dann unserer fertig decodierten Tabelle von vorher hinzu, indem Sie die Probanden-ID-Nummer als Schlüssel verwenden.
# A tibble: 9,254 × 6
subjectId age gender ethnicity height weight
<dbl> <dbl> <chr> <chr> <dbl> <dbl>
1 93703 2 female NH Asian 88.6 13.7
2 93704 2 male NH White 94.2 13.9
3 93705 66 female NH Black 158. 79.5
4 93706 18 male NH Asian 176. 66.3
5 93707 13 male other/multi 158. 45.4
6 93708 66 female NH Asian 150. 53.5
7 93709 75 female NH Black 151. 88.8
8 93710 0 female NH White NA 10.2
9 93711 56 male NH Asian 171. 62.1
10 93712 18 male Mexican 173. 58.9
# ℹ 9,244 more rows
Diesmal haben wir die Probanden-ID (subjectID, SEQN) als Schlüssel verwenden. Durch das relationship="one-to-one" weisen wir R an, zu überprüfen, dass die Probanden-IDs in beiden SPpalten eindeutig sind, also keine Probanden-ID mehrfach vorkommt, weder in der linken noch in der rechten Tabelle.
Nun haben wir die nhanes-Tabelle erstellt:
nhanes
# A tibble: 9,254 × 6
subjectId age gender ethnicity height weight
<dbl> <dbl> <chr> <chr> <dbl> <dbl>
1 93703 2 female NH Asian 88.6 13.7
2 93704 2 male NH White 94.2 13.9
3 93705 66 female NH Black 158. 79.5
4 93706 18 male NH Asian 176. 66.3
5 93707 13 male other/multi 158. 45.4
6 93708 66 female NH Asian 150. 53.5
7 93709 75 female NH Black 151. 88.8
8 93710 0 female NH White NA 10.2
9 93711 56 male NH Asian 171. 62.1
10 93712 18 male Mexican 173. 58.9
# ℹ 9,244 more rows
Weitere Joins
Der Vollständigkeit halber seien noch die anderen join-Verben aufgeführt
Bei left_join werden alle Zeilen der linken Tabelle beibehalten, und Zeilen aus der rechten Tabelle angefügt. Wenn die Zeile rechts fehlt, werden NAs angefügt.
Bei right_join sind die Rollen von linker und rechter Tabelle sind vertauscht: Alle Zeilen der rechten Tabelle werden beibehalten, aus der linken wird ausgewählt.
Bei inner_join werden nur die Zeilen zu den Schlüssel-Werten behalten, die in beiden Spalten vorkommen. NAs werden nie eingefügt, denn Zeilen, die in einer der Spalten fehlen, werden entfernt.
Bei full_join werden die Zeilen beider Tabellen behalten. Wenn der Schlüssel in einer der Tabellen fehlt, werden auf der jeweiligen Seite NAs ergänzt.
Bei einem semi_join werden gar keine Spalten angehängt. Statt dessen werden aus der linken Tabelle alle die Zeilen entfernt, die keine passende Zeile in der rechten Tabelle haben.
Auch bei einem anti_join werden keine Spalten angehängt. Hier werden aus der linken Tabelle alle Zeilen entfern, zu denen es eine passende Zeile in der rechten Tabelle gibt.
Meist kommt man aber mit dem left_join aus.
Hausaufgaben
Slack-Workspace
Bitte melden Sie sich auf unserem Slack-Workspace an. Dort können Sie jederzeit Fragen zu Vorlesung und Übung stellen.
Body-Measures-Tabelle
Laden Sie die Tabelle “BMX_J” von der NHANES-Webseite herunter und laden Sie sie in R. Selektieren Sie die Spalten mit der Probanden-ID, dem Körpergewicht in kg und der Körpergröße in cm. Benennen Sie die Spalten um zu “subjectId”, “weight” und “height”.
Fügen Sie diese Tabelle dann unserer fertig decodierten Tabelle von vorher (demo) hinzu, indem Sie die Probanden-ID-Nummer als Schlüssel für einen Table-Join verwenden.
Einkommensklassen
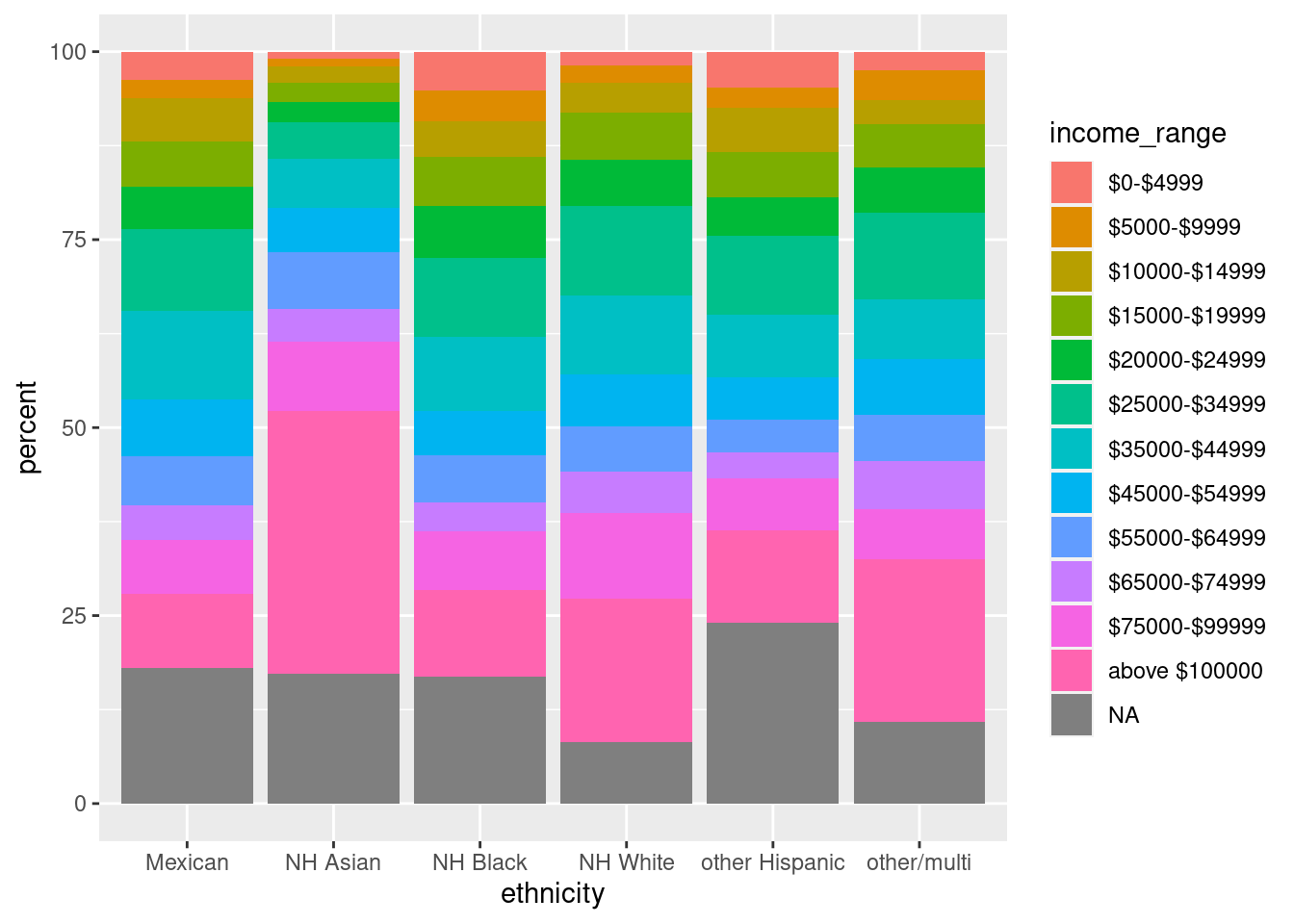
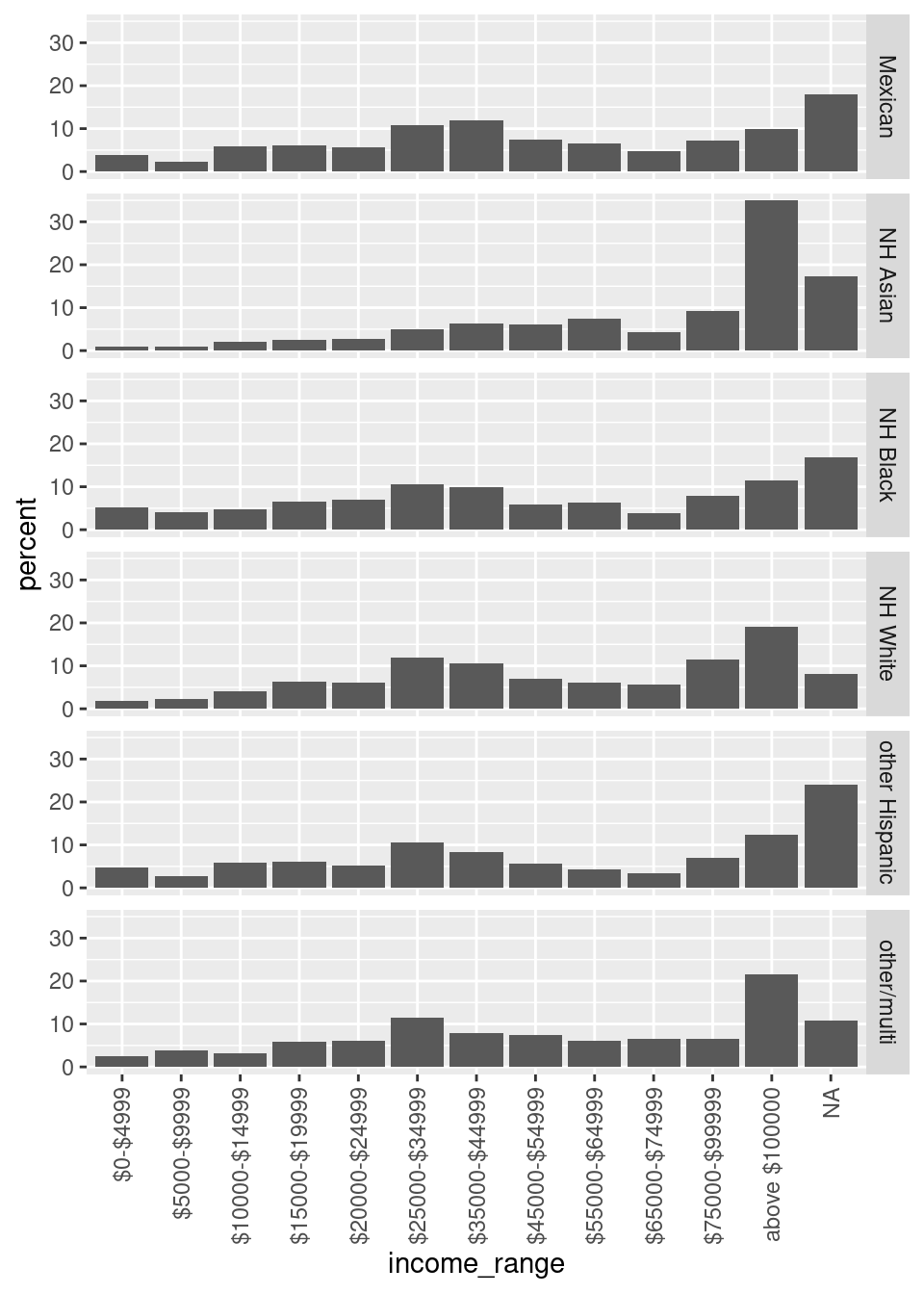
In der Tabelle DEMO_J finden Sie eine Spalte zum Haushaltseinkommen: INDHHIN2. Zählen Sie für jede Ethnie getrennt, wie viele Probanden in jede der Einkommensbereiche fallen. Stellen Sie Ihr Ergebnis in geeigneter Weise graphisch dar. Laden Sie Ihren Plot und Ihren Code auf Moodle hoch.
Zunächst nehmen wir den Code von oben (“Alles zusammen”) und fügen im select-Befehl noch die neue Spalte INDHHIN2 hinzu.
read_xpt( "Downloads/DEMO_J.XPT") %>%select( subjectId = SEQN, gender_code = RIAGENDR, age = RIDAGEYR, ethnicity_code = RIDRETH3,income_code = INDHHIN2 ) %>%# <<<<<< Nur diese Zeile ist neu <<<<<<<<left_join( gender_codes, by =c( "gender_code"="code" ), relationship="many-to-one" ) %>%left_join( ethnicity_codes, by =c( "ethnicity_code"="code" ), relationship="many-to-one" ) %>%select( -gender_code, -ethnicity_code ) -> demo0demo0
# A tibble: 9,254 × 5
subjectId age income_code gender ethnicity
<dbl> <dbl> <dbl> <chr> <chr>
1 93703 2 15 female NH Asian
2 93704 2 15 male NH White
3 93705 66 3 female NH Black
4 93706 18 NA male NH Asian
5 93707 13 10 male other/multi
6 93708 66 6 female NH Asian
7 93709 75 2 female NH Black
8 93710 0 15 female NH White
9 93711 56 15 male NH Asian
10 93712 18 4 male Mexican
# ℹ 9,244 more rows
Um nicht mit dem Code oben durcheinander zu kommen, heisst die Tabelle diesmal demo0 statt demo.
Nun konstruieren wir die Code-Tabelle. Man kann sie einfach abtippen, aber hier ist ein Weg, wie man das erleichtern kann. Wir beschließen zunächst, die Codes 12 und 13 auszulassen, da sie nicht ins Schema passen. Also bleiben wir bei den Codes von 1 bis 10 sowie 14 und 15, und schreiben uns dazu jeweils die Tausender der unteren Grenzen der Intervalle:
Achtung: Hier habe ich in der Vorlesung einen Fehler gemacht. Ich habe die Codes 1 bis 10 einfach mal 5000 genommen, dabei aber nicht gemerkt, dass es ab Code 8 in 10,000en-Schritten weiter geht. Deshalbn habe ich sie diesmal abgetippt.
Nun brache ich die Obergrenzen. Die nehme ich aus den untergrenzen der Vorherigen Zeile. Hier hilft uns die Funktion lead, die alle Werte in einem vektor um einen Schritt nach links schiebt:
lead( 1:10 )
[1] 2 3 4 5 6 7 8 9 10 NA
WIe man sieht, fällt der erste Wert weg und hinten wird ein NA angefügt.
Hier haben wir die Funtion str_glue benutzt, in der man einen String vorgeben kann, indem dann die Teile, die in geschweifte Klammern eigefügt sind, durch die entsprechenden Spalten ersetzt werden. Mann kann auch Rechnungen in die Klammern schreiben.
Leider ist die letzte Zeile (Zeile 12) komisch geworden; das bessern wir manuell aus, mit str_replace, das ein “Suchen und Ersetzen” in einem String-Vektor oder einer Spalte vornehmen kann:
Hier ist noch neu das fct_inorder in der letzten Zeile hinzugekommen. Es bedeutet: 1. Wandle die Spalte income_range in einen Faktor um, d.h. einen Vektor, indem nur eine vorgegebene begrenzte Liste von Strings vorkommen dürfen, weise jedem String eine Nummer zu und 2. weise die Nummern so zu, dass die zugelassenen Wörter in der Reihenfolge durchnummeriert werden, in der sie in der Spalte vorkommen.
Der erste Punkt ist allen Funktionen, die mit fct_ beginnen gemein, der zweite ist spezifisch für fct_inorder (hier “in order”, d.h. “in der Reihenfolge” wie angegeben).
Zweck der Sache ist, eine Reihenfolge festzulegen, in der diese Faktor-Levels dann z.B. in Plots anreordnet werden. Ohne das fct_inorder würde ggplot die Levels nämlich “lexikographisch” sortieren, d.h. alphabetisch, zusammen mit merkwürdigen Regeln, falls es (wie hier) keine Buchstaben sind.
Diese Code-Tabelle zu erzeugen war etwas kompliziert; man hätte sie aber auch einfach abtippen können, wie weiter oben gezeigt. Nun geht es aber weiter wie wir es bereits in der Vorlesung gesehen haben.
Zuerst “joinen” wir die Code-Tabelle, genauso wie weiter oben in diesem Skript:
Letzter Schönheitsfehler ist hier noch, dass es irreführend ist, dass die Balken bei $25k-$35k plötzlich größer werden, was aber nur daran liegt, dass dieser Balken eine Spanne von $10k abdeckt, der links davon aber nur $5k.
Man könnte dazu die Breite der Balken proportional zur Breite ihrer Spanne machen, und die Anzahl der Probanden im jeweiligen Einkommensinterval nicht durch die Höhe sondern durch die Fläche der Balken darstellen. Das nennt man die Histogramm-Regel. Sie ist aber hier schwierig umzusetzen, u.a., weil wir nicht wissen, wie weit der vorletzte Balken (“above $100000”) geht.