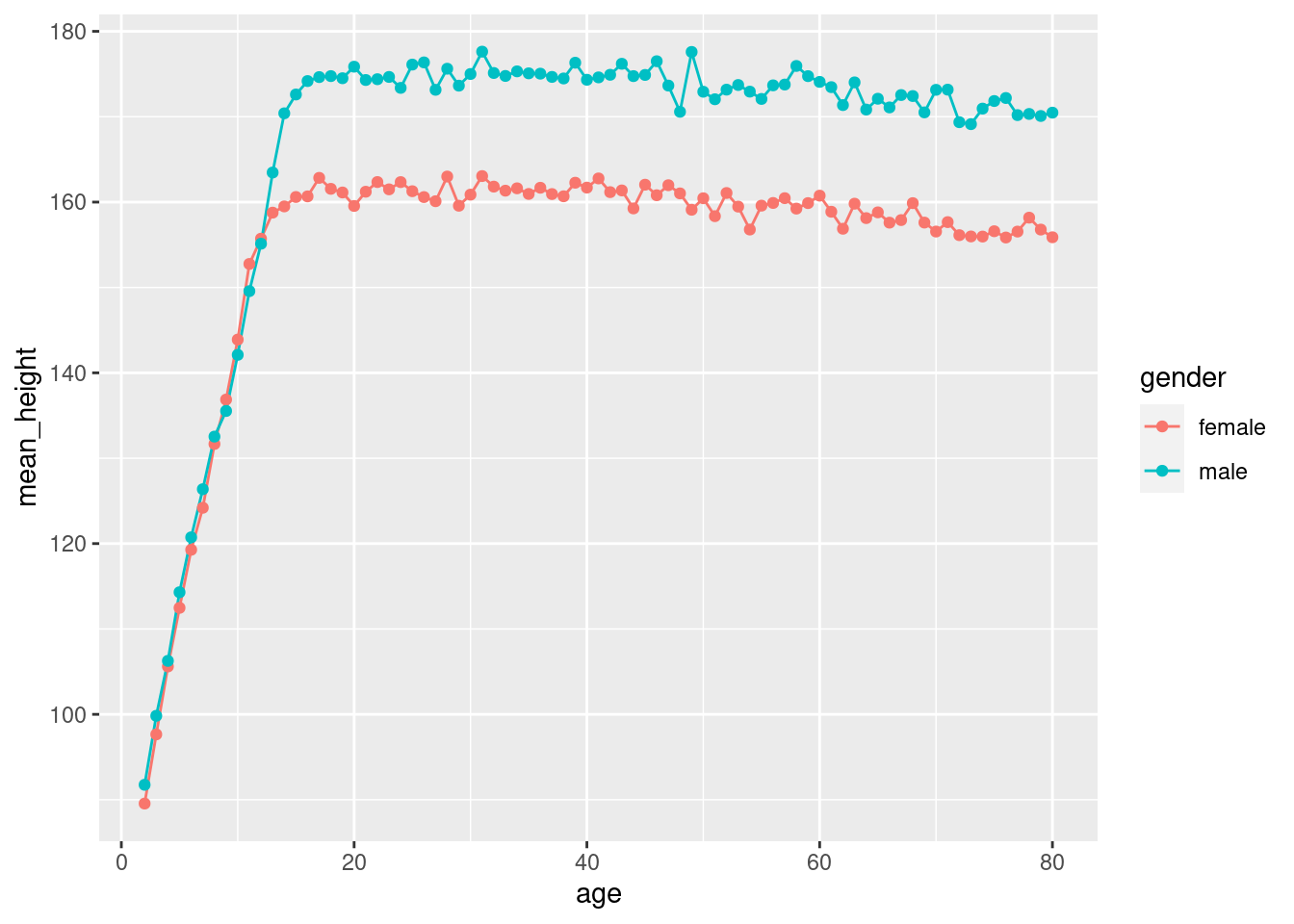
Bevor wir zum neuen Stoff kommen, erst die Hausaufgabe. Aufgabe war, einen Plot mit der Durschschnitts-Größe der Probanden jedes Jahrgangs, aufgeschlüsselt nach Geschlecht, zu erstellen.
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
Anmerkungen:
Wir gruppieren nach Geschlecht und Alter. Da “age” diskrete Werte (ganze Zahlen) hat funcktioniert das. Wenn “age” eine kontinuierliche Größe wäre (wie height), könnten wir keine Gruppen bilden, zumindest nicht, ohne vorher zu diskretisieren (z.B. durch Abrunden auf ganze Zahlen).
Wir haben hier zwei “Geoms”, die beide dieselben Daten verwenden. So erhalten wir Linien mit Punkten. Man kann einem Geom auch einen eigenen “aes()”-Block geben, wenn man möchte, das die geoms die Daten aus den Spalten verschieden verwenden.
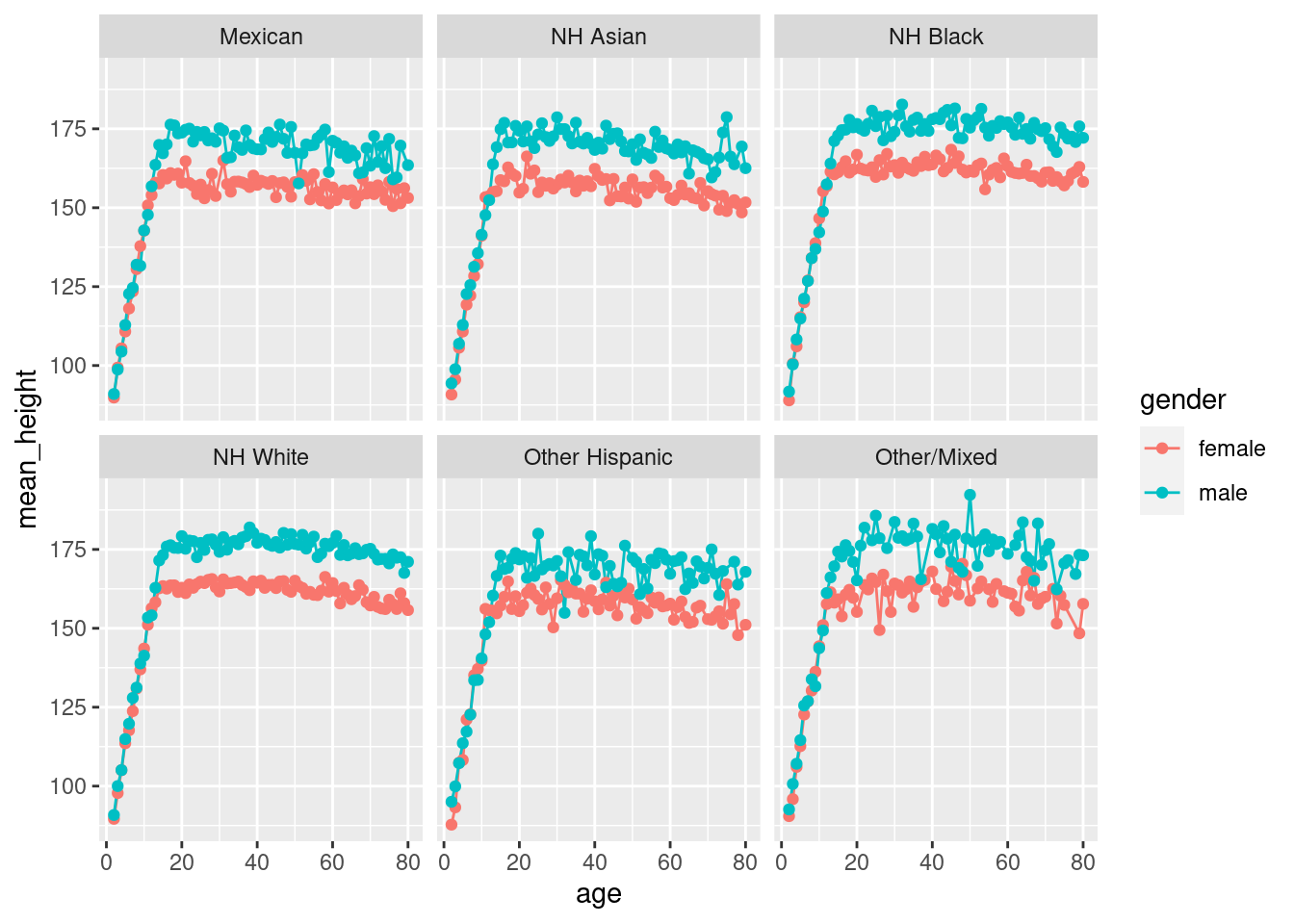
Durch Facetting können wir noch nach Ethnie separieren:
`summarise()` has grouped output by 'gender', 'age'. You can override using the
`.groups` argument.
Anmerkungen:
Wir haben hier “ethnicity” als dritte Gruppenvariable zu group_by hinzugefügt. Damit hat sich die Zahl der Gruppen versechsfacht.
Statt facet_grid habe ich diesmal facet_wrap verwendet. Es teilt die Plots in Kacheln auf, und ordnet die in einem Gitter an.
Inferenz: Erste Schritte
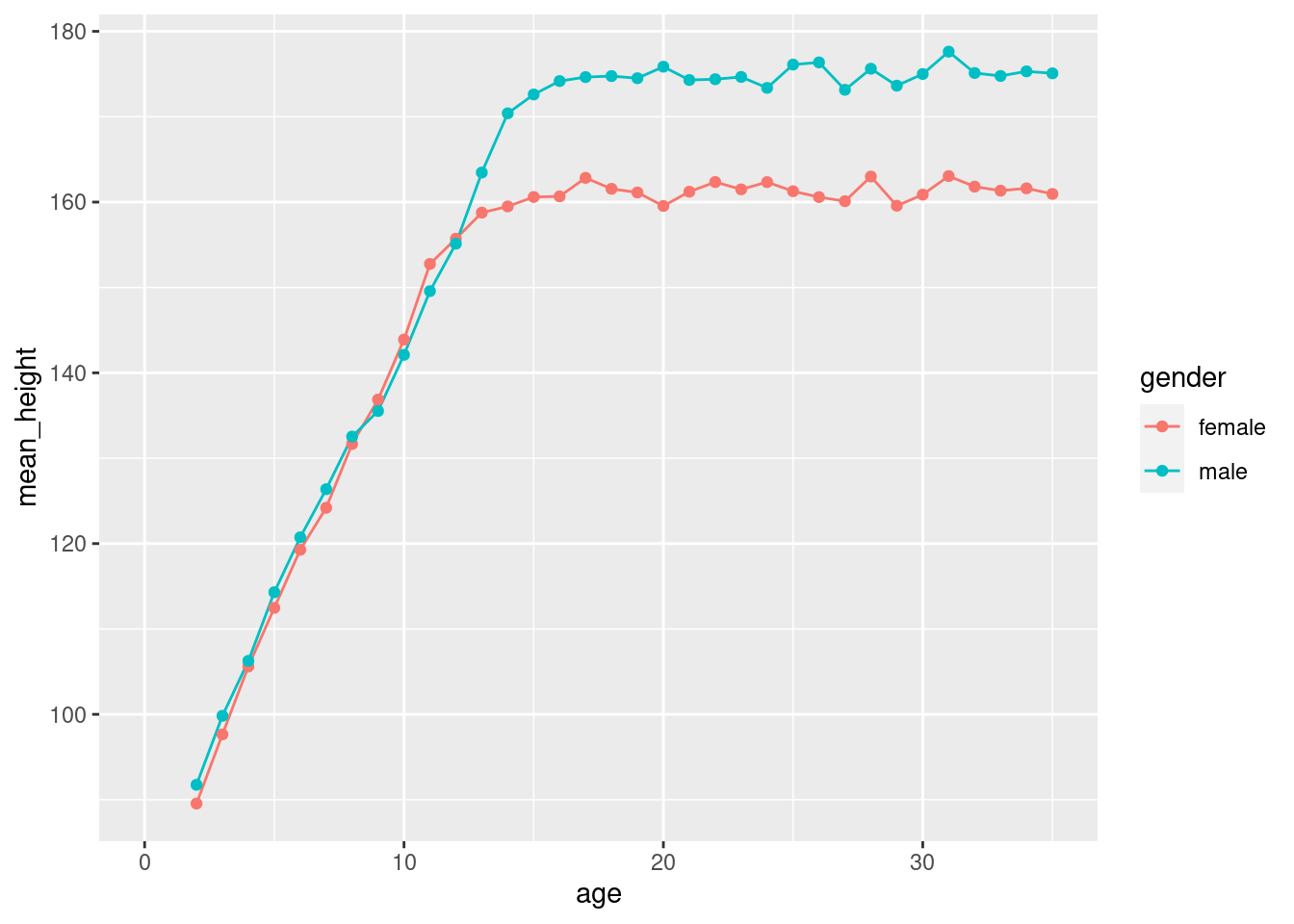
Sehen wir uns den ersten Plot nochmal genauer an und zoomen auf die linke Hälfte, indem wir in der x-Achse auf 0 bis 35 Jahre hinein zoomen (+ xlim( 0, 35 )).
Wir erkennen, dass Jungen und Mädchen in etwa bis zum 12. Lebensjahr gleich groß sind. Dann verlangsamt sich das Wachstum der Mädchen, wärend die Jungen noch 2 Jahre mit gleicher Geschwindigkeit weiter wachsen.
Im Alter von 11 Jahren scheinen die Mädchen aber etwas größer zu sein. Ist dieser Unterschied “echt” oder nur eine zufällige Fluktuation?
Anders ausgedrückt: ist dieser Unterschied statistisch signifikant?
Damit ist gemeint: Wenn die NHANES-Wissenschaftler ihre Untersuchung im selben Jahr wiederholt hätten, also nochmal so viele Probanden vermessen hätten, wäre zu erwarten, dass sich der Unterschied bestätigt hätte?
Oder auch: Wenn man im selben Jahr alle 11-jährigen Jungen und Mädchen vermessen hätte, die damals in den USA gelebt haben, könnten wir die Frage definitiv beantworten, ob damals die 11-jährigen Mädchen größer als die 11-jährigen Jungs gewesen sind. Dürfen wir annehmen, dass unser Ergebnis, das lediglich auf einer Stichprobe beruht, die Situation der Gesamtbevölkerung widerspiegelt?
Solche Fragen zu beantworten ist die Aufgabe der schließenden Statistik (inferential statistics).
Als Vorausschau betrachten wir einige Lösungsmöglichkeiten, die wir später genauer diskutieren werden.
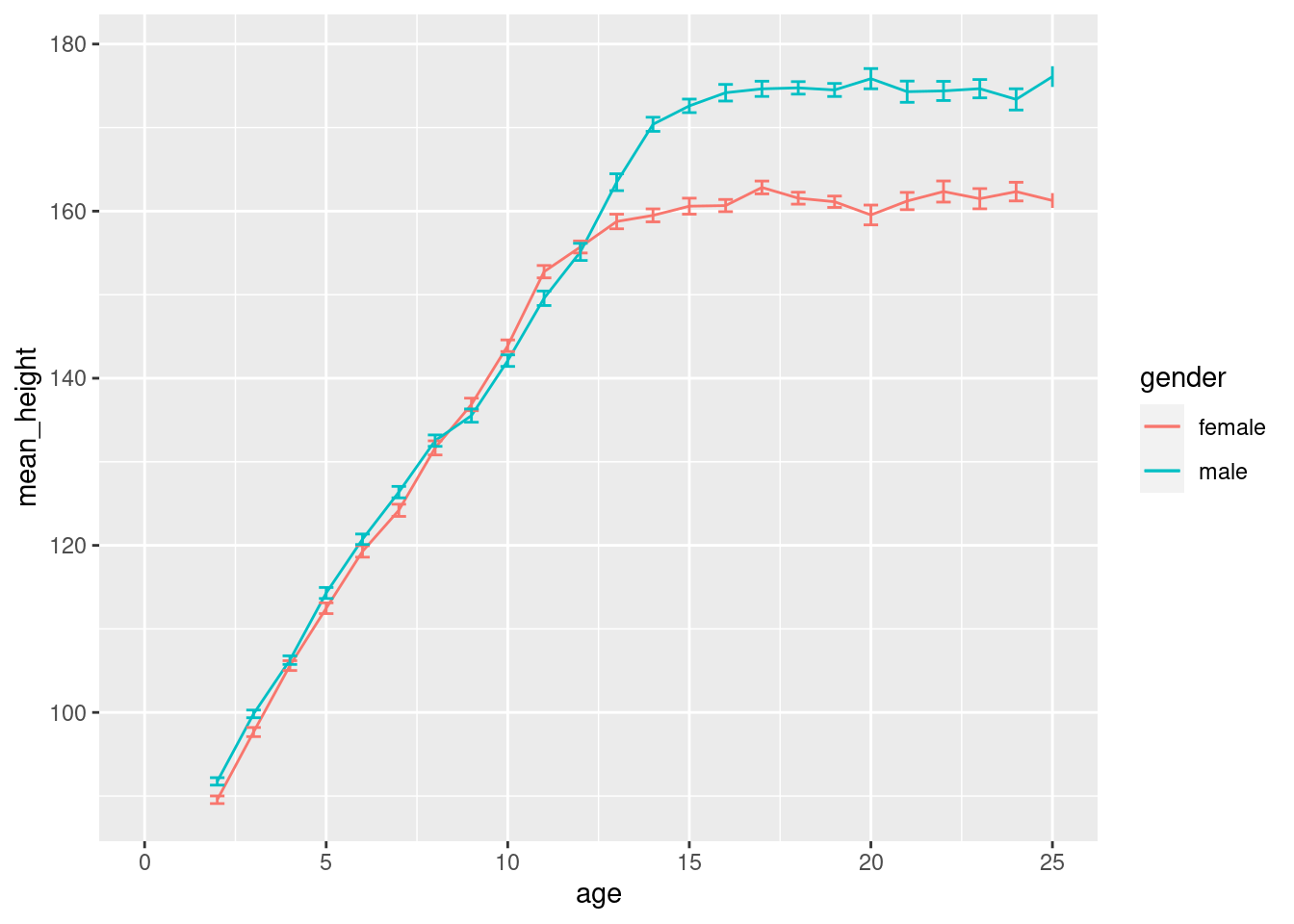
Standardfehler
In der Mathe-Vorlesung haben Sie gelernt:
Zieht man eine Stichprobe der Länge \(n\) (also eine Stichprobe mit \(n\) Werten) aus einer Verteilung mit Erwartungswert \(\mu\) und Standardabweichung \(\sigma\), so hat die Verteilung des Mittelwerts der Stichprobe ebenfalls den Erwartungswert \(\mu\), aber die Standardabweichung \(\sigma_\text{M} = \frac{\sigma}{\sqrt{n}}\). Dies bezeichnet man als den Standardfehler des Mittelwerts (standard error of the mena, S.E.M.)
Wenn sich die Fehlerbalken überlappen, gibt es keinen signifikanten Unterschied. Aber wie viel Lücke sollte zwischen den Fehlerbalken sein, damit wir glauben können, dass der Unterschied signifikant ist? Dass werden wir noch klären müssen.
t-Test
Sicher erinnern Sie sich noch an den t-Test.
Wir reduzieren die Tabelle auf nur die 11-jährigen:
nhanes %>%filter( age ==11, !is.na(height) )
# A tibble: 168 × 6
subjectId gender age height weight ethnicity
<dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 93733 female 11 143. 40.8 NH White
2 93736 male 11 143. 36.9 Mexican
3 93820 female 11 163. 72.6 NH Black
4 93922 male 11 148. 49.3 Other Hispanic
5 93928 male 11 166. 37.5 NH White
6 93997 female 11 160. 44.8 NH White
7 94009 female 11 155 48.5 Other Hispanic
8 94091 male 11 147. 40.7 Mexican
9 94107 female 11 141. 42.3 NH White
10 94257 male 11 146. 33 NH Asian
# ℹ 158 more rows
Welch Two Sample t-test
data: height by gender
t = 2.7816, df = 152.91, p-value = 0.00609
alternative hypothesis: true difference in means between group female and group male is not equal to 0
95 percent confidence interval:
0.9221609 5.4427418
sample estimates:
mean in group female mean in group male
152.7537 149.5712
Ein p-Wert von 0.6% – ist das signifikant? Auch dass werden wir noch besprechen müssen.
Zur Funtion t.test:
Diese Funktion erwartet als erstes Argument eine “Formel”, als zweites die Tabelle mit den Daten.
Die Tabelle mit den Daten haben wir mit dem Pipe-Pfeil %>% in die t-Test-Funtion hinein geschoben. Normalerweise schiebt der Pipe-Pfeil das, was links von ihm stellt, in die Position des ersten Arguments. Hier wird die Tabelle aber als zweites Argument erwartet. Der Punkt (.) im zweiten Argument markiert für den Pipe-Pfeil, wo die Tabelle hin soll. (Nur wenn der Punkt fehlt, wird ins erste Argument geschoben. Das ist eine Subtilität der Tidyverse-Pipes, die wir bisher übergangen haben.)
Zur “Formel” im ersten Argument:
In R heisst alles “Formel” (formula), was eine Tilde (~) enthält.
t.test liesst die Formel wie folgt:
Links von der Tilde steht der Name der Spalte, die die Werte enthält
Rechts von der Tilde steht der Name einer diskreten Spalte, die genau zwei verschiedene Levels enthält und so die Werte zwei Gruppen zuordnet.
Hier teilt die Spalte gender die Werte in height auf zwei Gruppen, male und female auf.
Die t.test-Funktion testet die Nullhypothese, dass der Mittelwerte der height-Werte in den beiden Gruppen derselbe ist.
Diskretisierung
Begriffe
Größen, die beliebige Werte innerhalb eines Wertebereichs annehmen können, heißen kontinuierlich (continuous). Beispiele hierfür in unserer NHANES-Tabelle sind height und weight.
Das Gegenteil von kontinuierlich ist diskret (discrete). (In den MINT-Fächern wird das Wort “diskret” oft in dieser Bedeutung, oder in der verwandten Bedeutung “einzeln, getrennt”, verwendet. Es hat nichts mit “geheim” zu tuin.)
In unserer Tabelle is age diskret, da auf ganze Jahre abgerundet wurde.
Ein wichtiger Sonderfall diskreter Größen sind Faktoren, d.h., Größen die nur bestimmte, aus einer vorgegebenen Gesamtheit entnommene Werte (die Levels) annehmen dürfen. Faktoren in unserer Tabelle sind gender (mit den 2 Levels male und female) und ethnicity (mit 6 Levels).
In R gibt es einen feinen Unterschied zwischen “character vectors” und “factors”. Unsere Tabellenspalten haben den Typ “character”; wir könnten ihn aber auf “factor” ändern. WO das einen unterschied macht, kommt später.
Diskretiserung durch Binning
Anfangs haben wir bemerkt, dass wir nur nach Alter gruppieren konnten, weil das Alter auf ganze Zahlen abgerundet ist und wir daher eine überschaubare Anzahl möglicher Werte haben. Bei Alter, Gewicht, oder BMI hingegen kommt wahrscheinlich nie exakt derselbe Werte zweimal vor. Wenn wir also nach solchen kontinuierlichen Werte gruppieren, wird jede Tabellenzeile in einer eigenen Gruppe landen.
Hier macht es oft Sinn, kontinuierliche Werte anhand eines Rasters aus Grenzen zu diskretisieren.
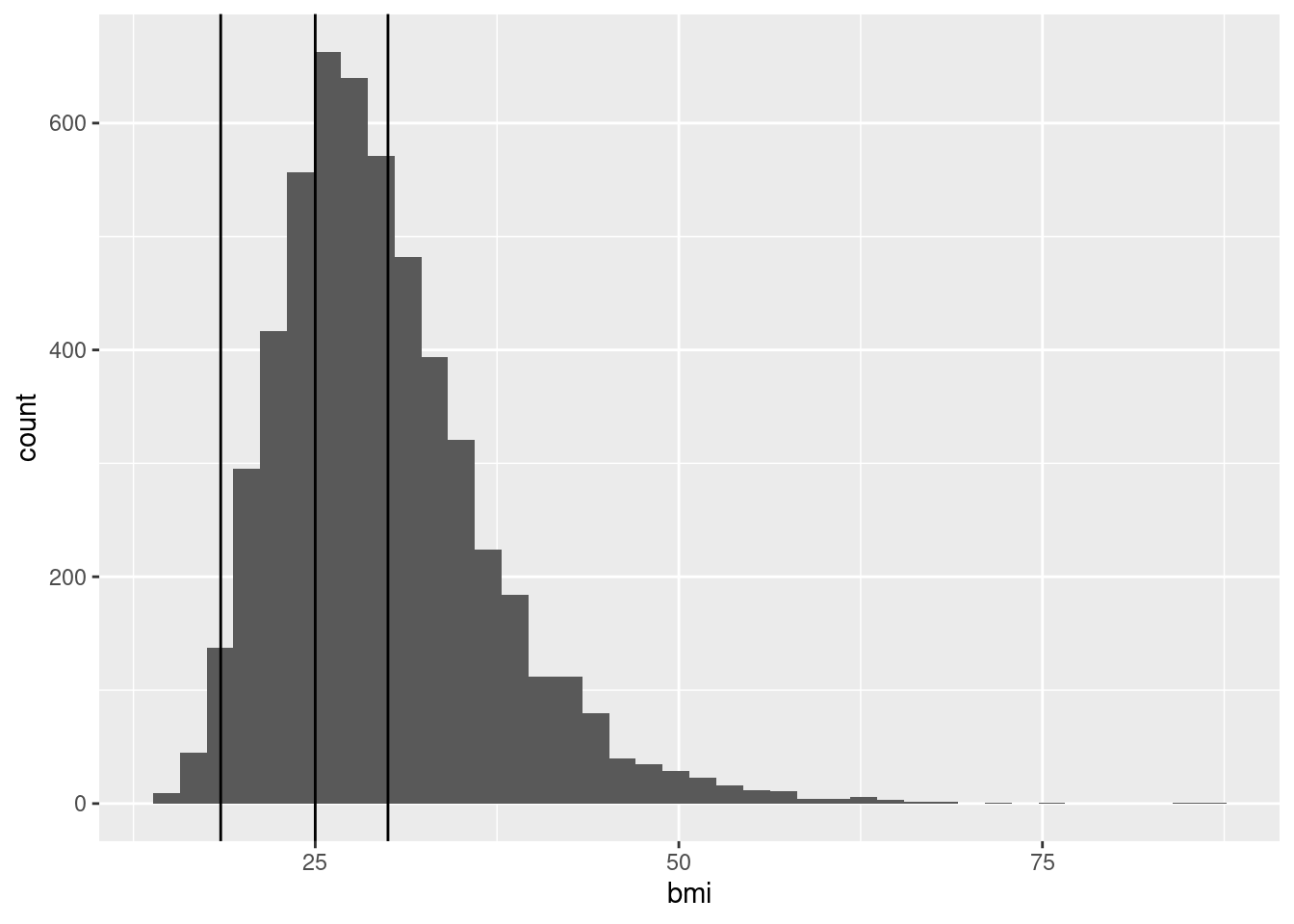
Beispiel 1: Beim Histogramm bildet R den Wertebereich auf ein Raster von “Bins” (Eimern) ab, und ordnet jeden Wert in eine Bin, die dann als ein Balken im Diagramm dargestellt wird.
Beispiel 2: Die WHO schlägt vor, BMI-Werte wie folgt zu interpretieren:
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
# A tibble: 8 × 3
# Groups: gender [2]
gender weight_state n
<chr> <fct> <int>
1 female underweight 57
2 female normal 743
3 female overweight 795
4 female obese 1216
5 male underweight 43
6 male normal 639
7 male overweight 930
8 male obese 1011
Hier haben wir bei summarise einen Spaltennamen angegeben, nämlich n (statt bisher n()), indem wir den gewünschten Spaltennamen, gefolgt von einem =, vor die Summarisierungs-Operation gesetzt haben.
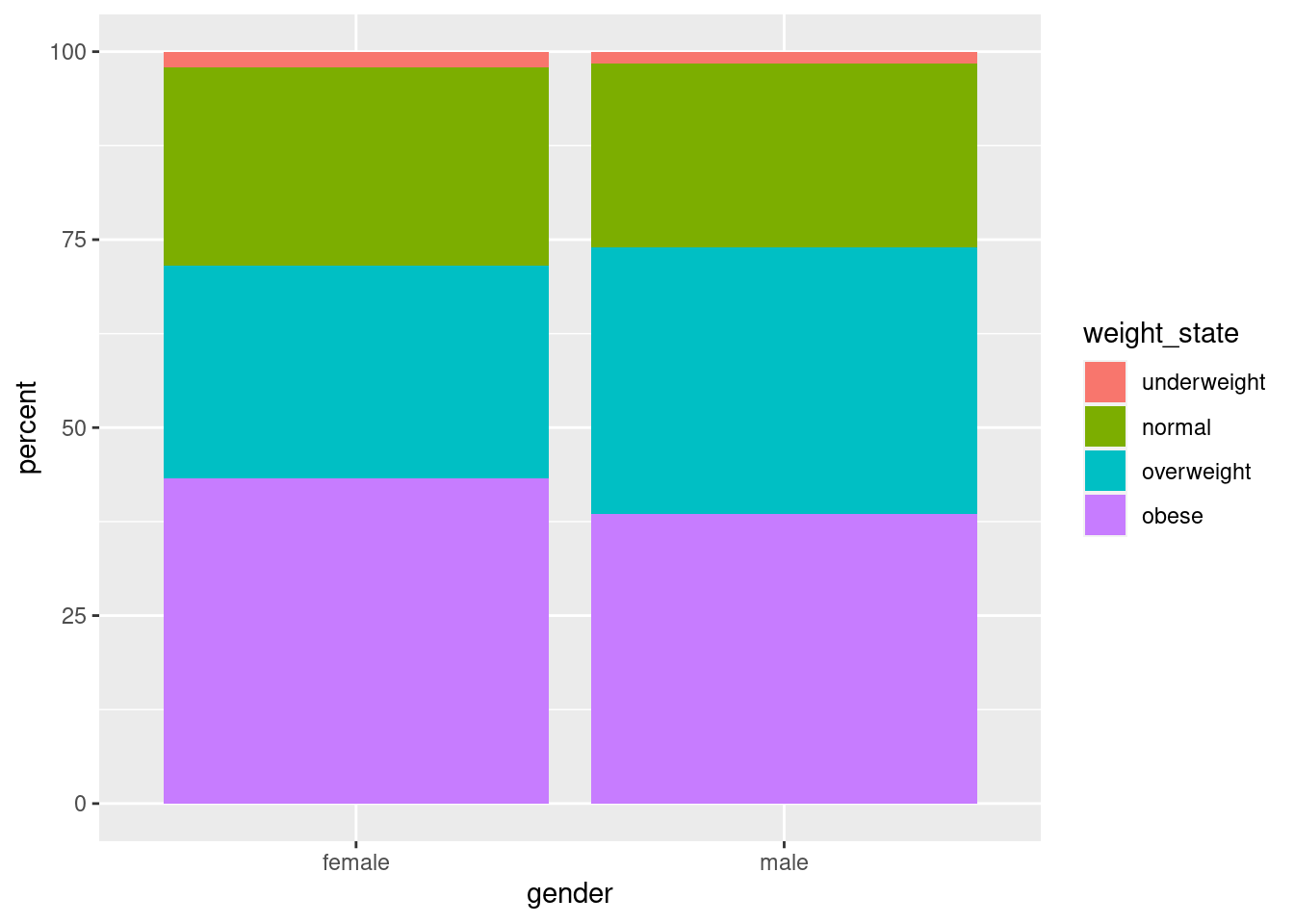
Nun möchten wir die diese Tabelle noch um eine Spalte mit Prozenten ergänzen:
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
bmi_perc
# A tibble: 8 × 4
# Groups: gender [2]
gender weight_state n percent
<chr> <fct> <int> <dbl>
1 female underweight 57 2.03
2 female normal 743 26.4
3 female overweight 795 28.3
4 female obese 1216 43.3
5 male underweight 43 1.64
6 male normal 639 24.4
7 male overweight 930 35.5
8 male obese 1011 38.5
Wie funktioniert dies?
Das zweite group_by teilt die 8 Zeilen in zwei Gruppen (male, female) zu je 4 Zeilen ein.
Das nachfolgende mutate wird für jede Gruppe getrennt durchgeführt. Daher ergibt sum(n) die Summe der Spalte nnur über die Zeilen der Gruppe. Jedes n wird also durch die Summe der vier n-Werte des jeweiligen Geschlechts geteilt. Somit addieren sich die Geschlechter jeweils getrennt zu 100%.
Zum Plotten verwenden wir ein gestapeltes Säulendiagramm (stacked bar chart):
Es gibt zwei Geoms für Bar-Charts: geom_col und geom_bar.
geom_col entnimmt die Höher der (Teil-)Säulen der in aes für y angegebenen Spalte.
geom_bar zählt, wie viele Zeilen es gibt, die denselben Wert micht – versucht also automatische zu machen, was wir schon manuell erledigt haben. Wir verwenden es hier nicht, da wir geom_bar nicht klar machen können, dass wir bereits auf 100% normalisiert haben.
In der Datentabelle, die wir ggplot gegeben haben, gibt es jeweils vier Zeilen mit demselben Wert in gender, der Spalte, die wir der x-Achse zugewiesen haben. Daher gibt es zu den beiden Positionen auf der x-Achse je 4 Säulen, die R einfach übereinander gestapelt hat.
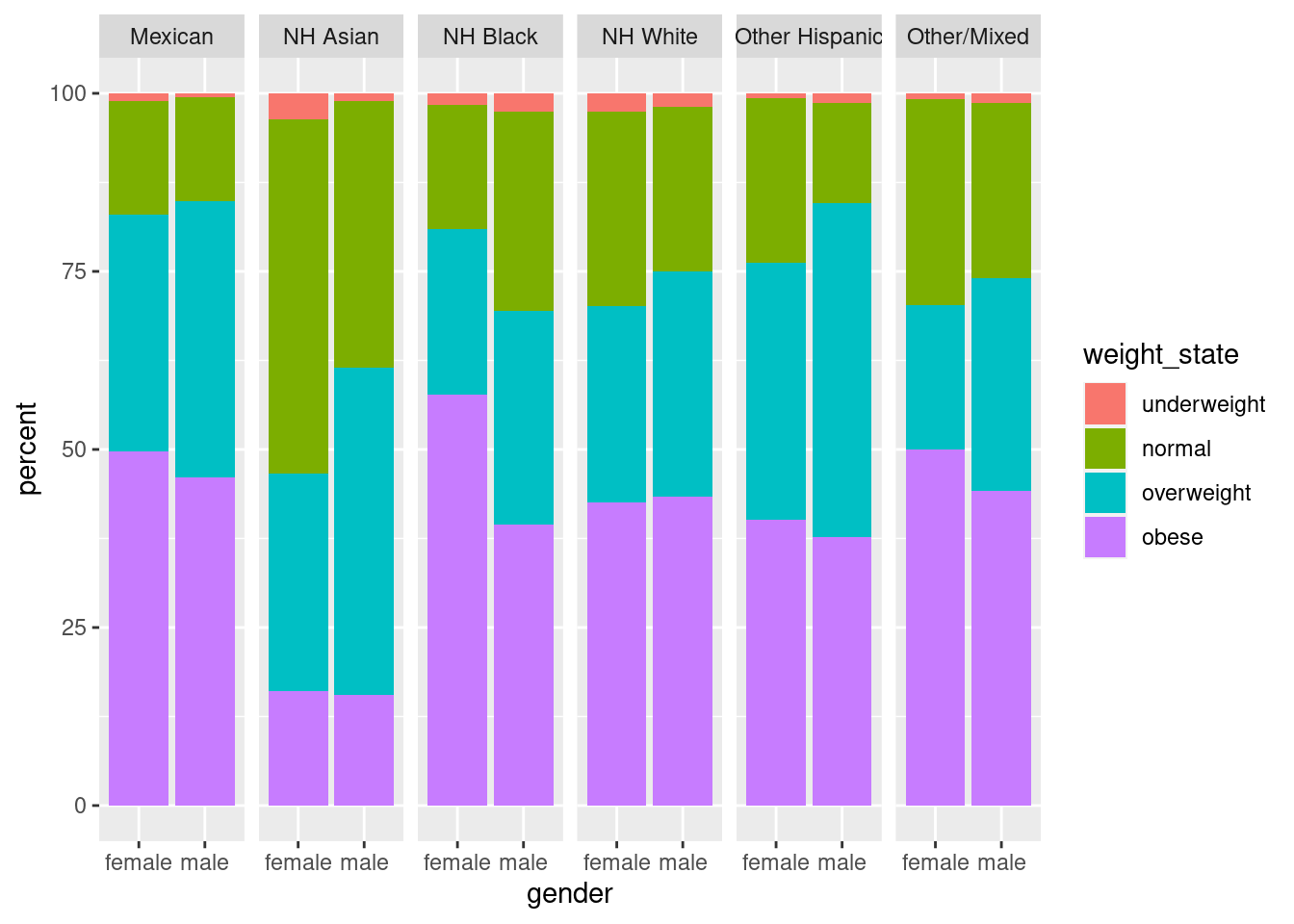
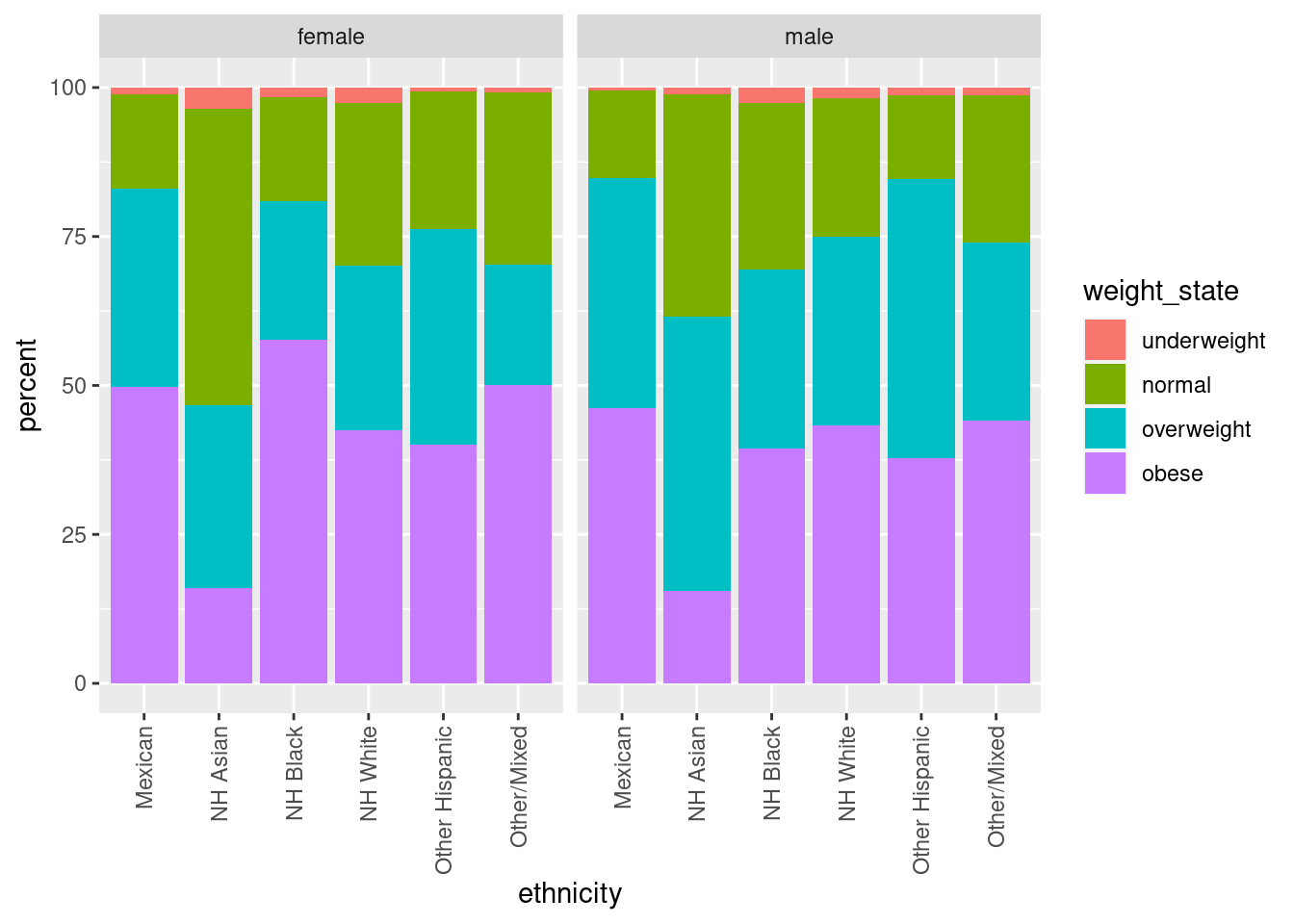
Hausaufgabe
Erweitern Sie diesen Plot, indem Sie nach Ethnie facettieren.
Lösung
Wir ändern den Code von oben leicht ab, indem wir bei den beiden group_bys noch ethnicity hinzufügen: