Berechnen Sie nochmals, wie schon in der vorigen Hausaufgabe, die durchschnittliche Körpergröße der erwachsenen Probanden aus der NHANES-Studie, aufgeschlüsselt nach Ethnie und Geschlecht.
Pivotieren Sie die Tabelle dann so, dass die Mittelwerte für die beiden Geschlechter nebeneinander statt untereinander stehen.
Aufgabe 2
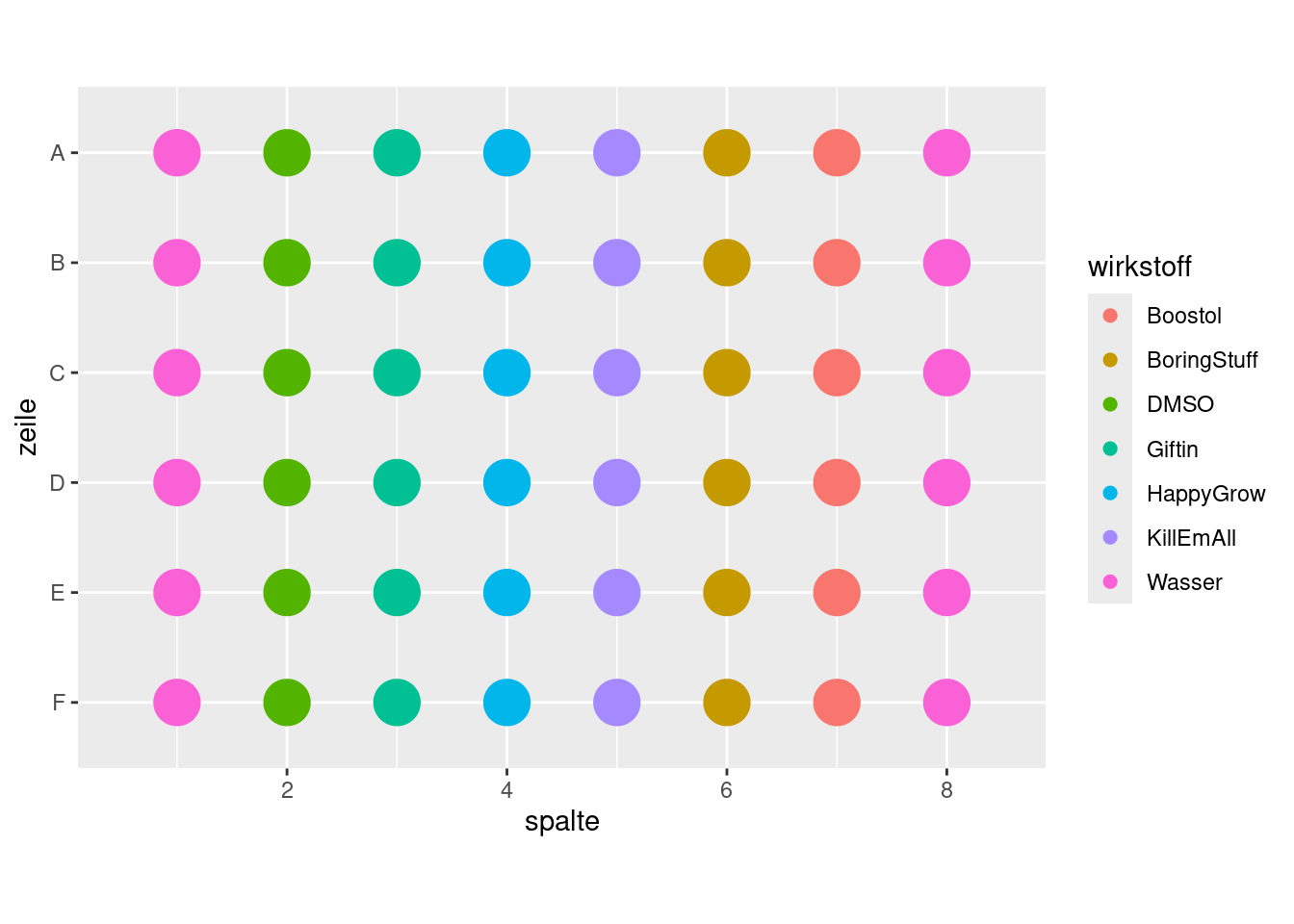
In einem Experiment soll der Einfluss verschiedener Wirkstoffe auf das Wachstum von Hefezellen gemessen werden. Dazu wird eine Suspension von Hefezellen in Wasser angesetzt. Die Suspension wird auf eine 48-Well-Platte verteilt; jedes Well erhält die gleiche Menge an Hefe. Anschließend werden die Wirkstoffe in die Wells gegeben. Jeweils 6 Wells, nämlich die, die in derselben “Spalte” der Platte liegen, erhalten denselben Wirkstoff. Die folgende Tabelle gibt an, welcher Wirkstoff in welche der 8 Spalten gegeben wurde:
Hier ist eine graphische Darstellung, wie die Wirkstoffe auf die Wells verteilt werden:
Anschließend wird in jedes Well eine für das Wachstum von Hefe geeignete Nährlösung hinzu gegeben, und die Platte dann für 3 Stunden bei 30 °C inkubiert.
Dann wird die Platte in einen. sog. Plattenscannner gegeben. Ein solche Scanner beleuchtet jedes Well von unten mit Licht einer vorgegebenen Wellenlänge und misst von oben, wie viel Licht durch das Well hindurch dringen kann. Je mehr Hefezellen im Well sind, desto trüber wird die Suspension, und desto größer ist die gemessene Licht-Absorption (optische Dichte, “OD”).
Der Plattenscanner erzeugt diese Excel-Datei als Ergebnis: example_plate_scan.xlsx. Laden Sie die Datei mit Excel (oder einem anderen Tabellenkalkulationsprogramm) und sehen Sie sie sich an.
Einlesen der Datei
Sie können diese Datei in eine CSV-Datei umwandeln und dann in R einlesen, oder Sie verwenden die Funktion read_excel aus dem Paket readxl, die Excel-Dateien direkt einlesen kann. In beiden Fällen müssen Sie die Zeilen über der eigentlichen Datentabelle entfernen. Bei read_xl können Sie hierzu das optionale Argument skip verwenden. So liest read_excel( "file.xls", skip=7) die Tabelle auf dem ersten Arbeitsblatt (Sheet) der Excel-Datei file.xls und überspringt dabei die ersten 7 Zeilen.
Die eingelesene Tabelle sollte 9 Spalten haben: 8 für die Spalten der Mikrotiterplatte und davor eine Spalte mit den Buchstaben, die die Zeilen nummerieren. Geben Sie dieser Spalte einen geeigneten Namen, z.B. zeile. Hierzu können Sie das Tidyverse-Verb rename verwenden.
Pivotieren
Pivotieren Sie die Tabelle in ein “tidy-table”-Format, d.h., sorgen Sie dafür, das jedes Well eine eigene Tabellen-Zeile hat. Sie sollten nun 3 Spalten haben, für Platten-Zeile, Platten-Spalte, und Messwert.
Streudiagramm
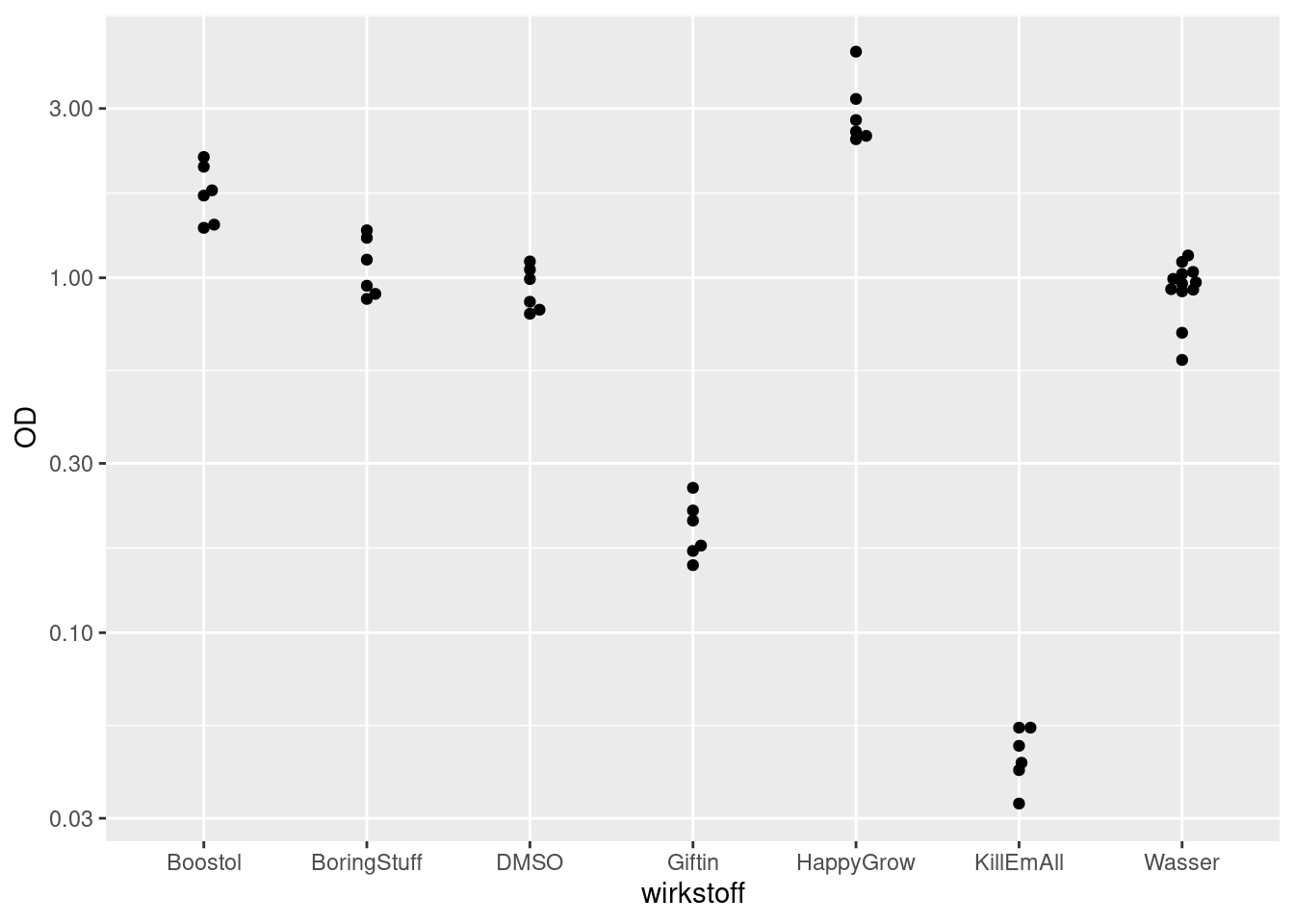
Erzeugen Sie nun ein Streudiagramm, dass die gemessen optische Dichte für jeden Wirkstoff darstellt. Es könnte in etwa so aussehen:
Anmerkungen:
Sie müssen hierzu die Tabelle mit den Messwerten und die Tabelle mit den Wirkstoffen zusammenführen. Dabei wird Ihnen auffallen, dass der Datentyp der Tabellen-Spalten spalte nicht zusammen passt. Mit mutate und as.numeric oder as.character können Sie das beheben, indem Sie den Datentyp der Spalte in einer der beiden Tabellen ändern.
Warum ist es günstig, die y-Achse logarithmisch darzustellen?
Wenn Sie geom_point verwenden, werden alle Punkte zum selben Wirkstoff genau übereinander gesetzt. Ich habe hier geom_point durch geom_beeswarm (vom )aus dem Paket ggbeeswarm) ersetzt, da dieses geom Punkte leicht versetzt, wenn sie sonst übereinander liegen würden. Diese Art der Darstellung nennt man einen “Beeswarm-Plot”.
Mittelwerte
Ermitteln Sie nun noch die Mittelwerte der OD-Werte für jeden Wirkstoff.
Nützlich wäre auch, diese Mittelwerte durch den Mittelwert für Wasser zu teilen, um leichter zu sehen, welche Wirkstoffe das Wachstum fördern und welche es hemmen.
Platten-Plot
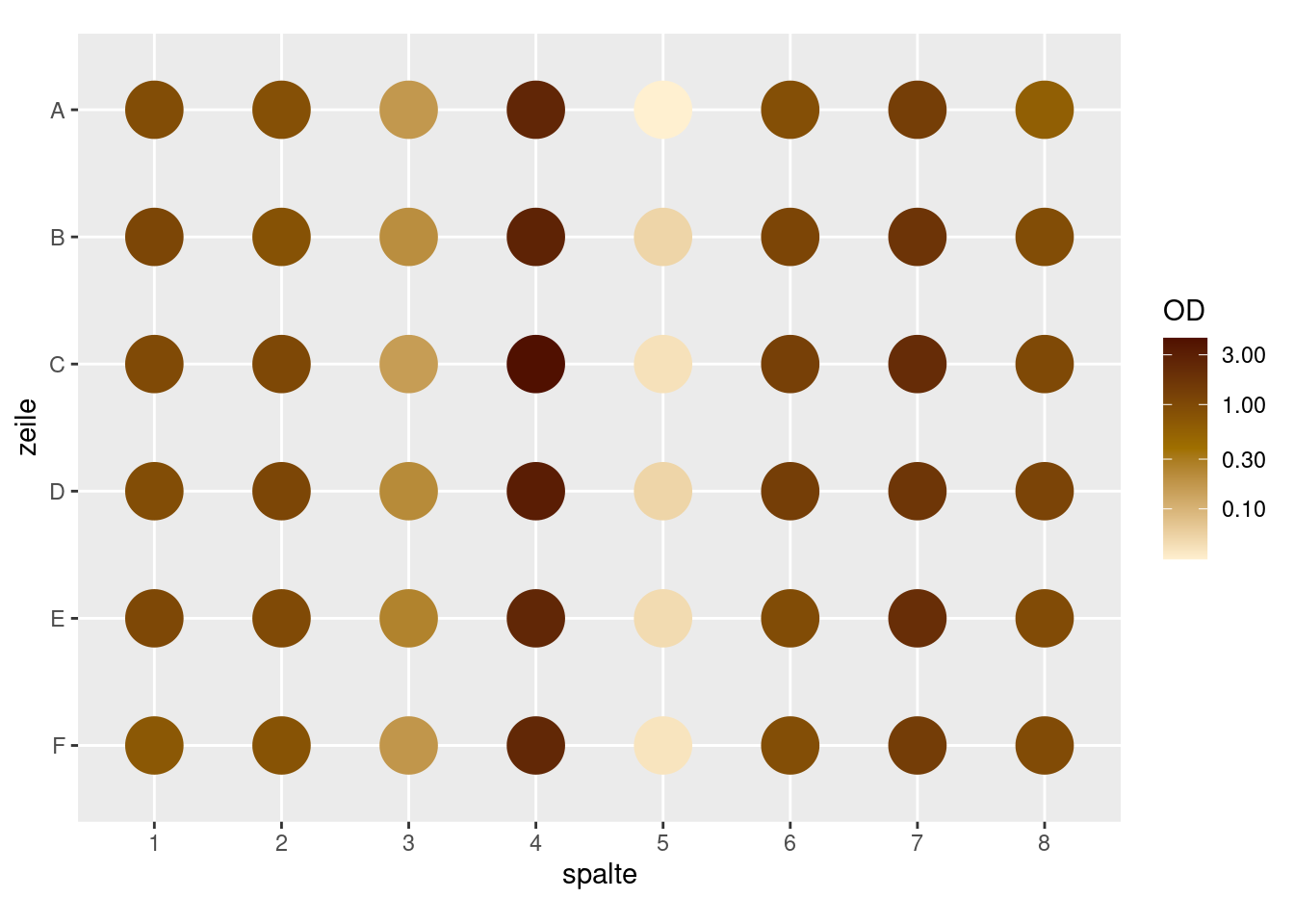
Versuchen Sie nun, diesen Plot hier zu erzeugen, der die Messergebnisse im Platten-Layout darstellt:
In diesem Plot habe ich einige Feinheiten geändert, so dass ihr Plot anders aussehen könnte. Ich habe die Punkte extra groß gemacht, damit sie wie Wells aussehen, und ich habe die y-Achse umgekehrt (weil Zeilen in Mikrotiterplatten von oben nach unten numeriert werden, ggplot die y-Achse aber von unten nach oben ansteigen lässt), die Farbskala logarithmisch gemacht, und die Palette geändert. Wenn Sie möchten, können Sie versuchen, durch geschicktes Googeln einige dieser Punkte auch zu erreichen (oder bitten Sie ChatGPT, Ihren Code zu verbessern ;-) ).
Einen solchen Plot benutzt man gerne, um sicher zu stellen, dass es keine Pippetierfehler oder Randeffekte gab.
Aufgabe 3: Stichproben-Mittelwert
Hier finden Sie eine weitere Aufgabe, die nicht zum Thema gehört, und daher auf einer separaten Seite liegt. Probieren Sie das aber bitte trotzdem, als Vorbereitung zum nächsten Thema.