state abb region population total
1 Alabama AL South 4779736 135
2 Alaska AK West 710231 19
3 Arizona AZ West 6392017 232
4 Arkansas AR South 2915918 93
5 California CA West 37253956 1257
6 Colorado CO West 5029196 65
Nun berechnen wir die Mordrate pro Region
murders %>%group_by( region ) %>%summarise( population =sum(population), murders =sum(total) ) %>%mutate( rate = murders / population *100000 )
# A tibble: 4 × 4
region population murders rate
<fct> <dbl> <dbl> <dbl>
1 Northeast 55317240 1469 2.66
2 South 115674434 4195 3.63
3 North Central 66927001 1828 2.73
4 West 71945553 1911 2.66
Abtasten einer Tidyverse-Pipeline: Wenn Sie verstehen wollen, wie dieser Code funktioniert, führen Sie ihn Schritt für Schritt aus, indem Sie zunehmend größere Teile des Codes markieren, immer vom Anfang bis direkt vor ein Pipe-Symbol %>%, und führen Sie diesen Code aus. So sehen Sie, wie die Tabellen mit Zwischenergebnissen aussehen, die durch das Pipe-Symbol geschoben werden.
# A tibble: 2 × 2
gender avg_height
<chr> <dbl>
1 female 160.
2 male 173.
Hier mussten wir na.rm=TRUE anfügen, um dafür zu sorgen, dass fehlende Werte übersprungen werden. Näheres dazu siehe unten.
Pfade zu Dateien
[…]
Aufgabe
Speichern Sie die Tabelle mit den Mordraten pro Region (s.o.) im CSV-Format. Verwenden Sie dazu write_csv, wie folgt
tabelle %>%write_csv( "tabelle.csv" )
Laden Sie die Datei tabelle.csv in Microsoft Excel oder in einem anderen Tabellenkalkulationsprogramm.
Erstellen Sie in Excel eine Tabelle mit einigen Spalten und Zeilen. Achten Sie darauf, dass die Spaltenüberschriften in der ersten Zeile stehen. Erstellen Sie mindestens eine Spalte mit numerischen Werten und eine mit Strings. Speichern Sie die Tabelle im CSV-Format. Laden Sie die Tabelle dann in R mit read_csv. (Wenn das nicht funktioniert, versuchen Sie read_csv2).
Fehlende Daten
In der Statistik hat man oft mit fehlenden Daten (missing data) zu tun. In R wird ein fehlender Wert durch NA (für “not available”) gekennzeichnet.
Eine Rechnung, die einen fehlenden Wert enthält, ergibt ein fehlendes Ergebnis:
7+NA
[1] NA
Fehlende Daten sind somit “ansteckend”, wie das folgende Beispiel zeigt.
Hier ist die Arbeitslosenstatistik des fiktiven Landkreises “Zettkreis”:
# A tibble: 1 × 2
`sum(Einwohner)` `sum(Arbeitslose)`
<dbl> <dbl>
1 67830 NA
Das funktioniert nicht, denn eine das eine NA hat sich forgepflanzt.
Wir können alle Zeilem entfernen, bei denen ein NA steht. Dazu brauchen wir die Funktion is.na. Sie gibt TRUE, wenn ein Wert fehlt:
is.na( c( 13, 15, 7.2, NA, -3.5 ) )
[1] FALSE FALSE FALSE TRUE FALSE
filter soll aber die Zeilen behalten, wo keinNA steht. Wir müssen den von is.na gelieferten logischen Vektor in sein Gegenteil umkehren. Dazu dient der “Nicht-Operator” (logical-not operator), der als ! geschrieben wird:
!is.na( c( 13, 15, 7.2, NA, -3.5 ) )
[1] TRUE TRUE TRUE FALSE TRUE
Das können wir für filter verwenden:
zett_tabelle %>%filter( !is.na(Arbeitslose) )
# A tibble: 3 × 3
Gemeinde Einwohner Arbeitslose
<chr> <dbl> <dbl>
1 Astadt 13245 1020
2 Bedorf 12716 832
3 Deburg 33417 1995
Nun können wir zumindest mit diesen Daten rechnen:
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
# A tibble: 12 × 3
# Groups: gender [2]
gender ethnicity avg_height
<chr> <chr> <dbl>
1 female Mexican 157.
2 female NH Asian 156.
3 female NH Black 162.
4 female NH White 161.
5 female Other Hispanic 157.
6 female Other/Mixed 162.
7 male Mexican 170.
8 male NH Asian 170.
9 male NH Black 176.
10 male NH White 175.
11 male Other Hispanic 169.
12 male Other/Mixed 176.
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
# A tibble: 12 × 4
# Groups: gender [2]
gender ethnicity avg_height n
<chr> <chr> <dbl> <int>
1 female Mexican 157. 377
2 female NH Asian 156. 418
3 female NH Black 162. 667
4 female NH White 161. 947
5 female Other Hispanic 157. 277
6 female Other/Mixed 162. 128
7 male Mexican 170. 362
8 male NH Asian 170. 366
9 male NH Black 176. 594
10 male NH White 175. 926
11 male Other Hispanic 169. 228
12 male Other/Mixed 176. 154
Regeln für group_by / summarize
Die Tabelle, die von einem summarize erzeugt wird, enthält nur Spalten mit Gruppierungs-Variablen und Spalten mit Summarisierungs-Ergebnissen.
Die Gruppierungs-Variablen sind die Spalten, die zuvor mit group_by gewählt wurden. Sie erscheinen in der Ergebnistabelle zunächst.
Dann folgen die Ergebnisse der Summarisierung(en), die in summerize angefordert wurde(n).
Eine Summarisierung (auch “Reduktion” genannt) ist ein Ausdruck,
in die R die zu eine Gruppe gehörenden Werte der Spalten als Vektoren hineingibt
und der hieraus einen einzelnen Wert erzeugt.
Beispiele für Summarisierungen:
mean(height), oder auch mean(height)/100
keine Summarisierung: height/100
In summerize kann man vor jede Summarisierungs-Operation den gewünschten Spaltennamen mit = voranstellen.
Häufig verwendete Summerisierungsfunktionen: - sum (Summe) - mean (Mittelwert) - median (Median) - n (Anzahl der Werte) - var und sd (Varianz und Standardabweichung)
Zählen
Wenn man sum auf einen logischen Vektor anwendet, erhält man die Anzahl der TRUEs:
v <-c( -2, 3, 7, 10, 0 )v >5
[1] FALSE FALSE TRUE TRUE FALSE
sum( v>5 )
[1] 2
Wie zuvor kann man NAs ggf. überspringen:
v <-c( -2, NA, 7, 10, 0 )v >5
[1] FALSE NA TRUE TRUE FALSE
sum( v>5 )
[1] NA
sum( v>5, na.rm=TRUE )
[1] 2
Hausaufgaben
Diesmal sind es etwas mehr Aufgaben. Versuchen Sie sich bitte an allen, damit Sie Routine mit R bekommen.
Aufgabe 1
Diese Aufgabe hatten wir am Ende der Vorlesung bereits angefangen, gemeinsam zu bearbeiten.
Zählen Sie, wie viele Probanden in der NHANES-Tabelle größer als 190 cm sind.
Gruppieren Sie nach Geschlecht und Ethnie. Zählen Sie für jede Gruppe getrennt, wie viele Probanden insgesamt in der Gruppe sind, und wie viele über 190 cm groß sind.
(Die Lösung zu dieser Aufgabe können Sie sich zusammen bauen, indem Sie mit dem Beispielcode oben aus dem Abschnitt “Mehrere Gruppenvariablen” beginnen, und diesen abändern, indem sie Konstruktion mit sum aus dem Abschnitt “Zählen” verwenden – denn was sich geändert hat ist dass wir nicht mehr fragen, was der Mittelwert der Körpergröße ist, sondern statt dessen, wie viele Probanden größer als 190 cm sind. Beides wird durch eine Summarisierungs-Operation gelöst.)
Berechnen Sie für jede Gruppe den prozentualen Anteil an Über-1.9-Meter-Probanden.
Aufgabe 2
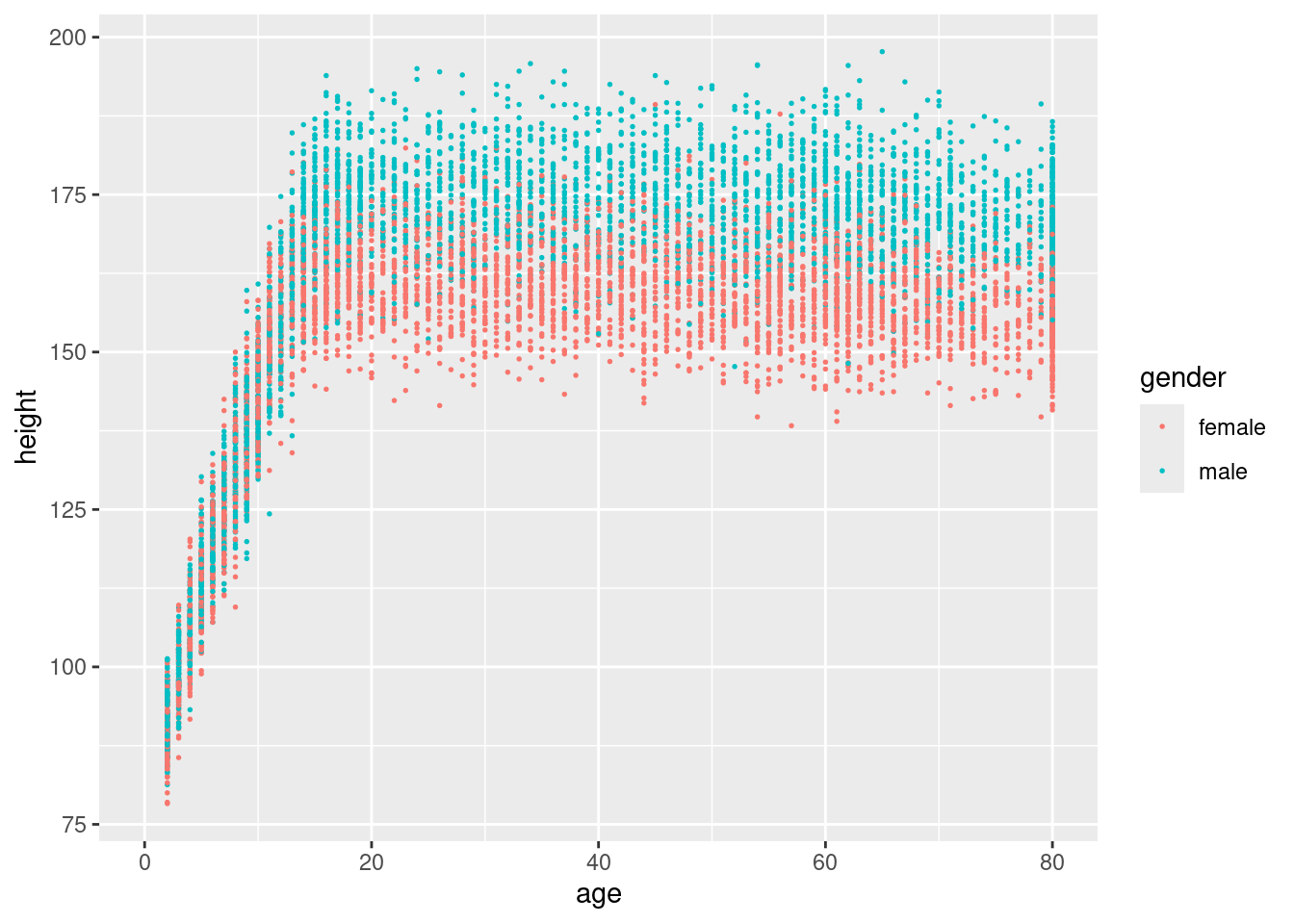
In der Hausaufgabe der vorigen Woche wir in der NHANES-Tabelle die mittlere Körpergröße, aufgeschlüsselt nach Geschlecht und Ethnie, berechnet. Schlüsseln Sie diesmal nach Geschlecht und Alter auf.
Erzeugen Sie einen Plot, der die Durschnittsgröße von Frauen/Mädchen und von Männern/Jungen für jedes Lebensalter darstellt.
Interpretieren Sie den Plot: Wie unterscheidet sich das Wachstum von Jungen und Mädchen?
Wie viele Zentimeter wächst ein Junge oder ein Mädchen im Mittel pro Jahr? Wie ändert sich die Wachstums-Geschwindigkeit von über die Jahre? Zu welchem Alter hört man tyoischerweise auf, weiter zu wachsen?
Vielleicht hilft es, in der x-Achse des Plots hineinzuzoomen, und die Achse nur von 0 bis 30 Jahre laufen zu lassen. Googlen Sie, wie man den auf der Achse dargestellten Wertebereich (“axis limits”) ändert, wenn man “ggplot” verwendet.
Aufgabe 3
Bauen Sie Schritt für Schritt eine Tidyverse-Pipeline wie folgt auf:
Beginnen Sie mit der NHANES-Tabelle
Entfernen Sie Probanden, wo die Körpergröße oder das Gewicht fehlt, sowie Probanden mit Alter unter 18 Jahren.
Fügen Sie eine Spalte bmi hinzu, die den Body-Mass-Index berechnet. Die Formel lautet wie folgt
\[ \text{BMI} = \frac{\text{Gewicht in kg}}{(\text{Körpergröße in Meter})^2} \] Denken Sie bei der Anwendung der Formel daran, dass unsere Tabelle die Körpergröße in Centimeter enthält. Sie müssen also (height/100) schreiben.
Erwachsene mit einem BMI über 25 gelten laut WHO-Leitlinien als übergewichtig. Bei einem BMI über 30 liegt krankhaftes Übergewicht (“Adipositas”) vor. Zählen Sie, wie viele Probanden übergewichtig sind und wie viele adipös.
Ermitteln Sie diese Zahlen aufgeschlüsselt nach Geschlecht und Ethnie, und rechnen Sie sie in Prozent um.
Ersatzergebnis: Das korrekte Ergebnis, zum Vergleichen, finden Sie hier: nhanes_bmi_smr.csv
Erstellen Sie nun ein Diagramm der Übergewichts-Anteile. Verwenden Sie Ethnie als x-Achse, Prozent übergewichtig als y-Achse, und stellen Sie das Geschlecht durch die Farbe dar. Ersetzen Sie dann geom_point( aes(...) ) durch geom_col( aes(...), position="dodge") und dann noch col durch fill. Sie sollten ein Säulendiagramm (auch Balkendiagramm genannt, engl. bar chart) erhalten.
Aufgabe 4
Datenaustausch mit Excel: In der Vorlesung hatten einige von Ihnen hier Schwierigkeiten. Inzwischen habe ich nachgeschlagen, woran das lag. Versuchen Sie es also bitte nochmals:
Wählen Sie eine beliebige Tabelle, wie sie vielleicht als Ergebnis bei einigen der vorherigen Übungen erzeugt wurde und speichern Sie sie als CSV-Datei:
tabelle %>%write_csv( "tabelle.csv" )
Die Datei liegt nun im Format “comma-separated values” vor.
Benutzen Sie einen Text-Editor und laden Sie die Datei. Der Standard-Texteditor von Windows heißt “Notepad”; bei MacOS heisst er “TextEdit”. Sie werden sehen, wie das CSV-Format aussieht: Jede Zeile der Tabelle ist eine Textzeile, die allererste Zeile enthält die Spaltennamen, und die Spalten sind durch Kommas getrennt. Daher der Name: “CSV” steht für “comma-separated values”.
Das Problem: Im Deutschen wird das Komma als Dezimaltrenner verwendet. (Im Deutschen schreibt man “1,5” für 1½, im Englischen “1.5”.) Daher weicht Excel aus und verwendet ein Semikolon (Strichpunkt) als Spaltentrenner, wenn man bei der Installation von Office deutsch und nicht englisch ausgewählt hat. R hingegen benutzt immer das englische Format (“.” als Dezimaltrenner, “,” als Spaltentrenner), wenn man read_csv oder write_csv benutzt, bietet aber read_csv2 und write_csv2 als Alternative an. Letztere Funktionen arbeiten mit dem Alternativformat (“,” als Dezimaltrenner, “;” als Spaltentrenner), das ein Excel erwartet, das auf Deutsch (oder eine andere Sprache mit Komma statt Punkt als Dezmialtrenner) eingestellt ist.
Laden Sie die Datei in Excel. Damit das klappt müssen Sie den sog. “Import-Wizard” verwenden, denn dort könenn Sie angeben, ob die Spalten durch Kommas oder Strichpunkte getrennt sind.
für ältere Office-Versionen: Starten Sie Excel, und wählen Sie im Menü “Datei” (“File”) die Funktion “Datei öffnen” (“Open file”). Im Lade-Dialog steht rechts unten, dass nur Excel-Dateien angezeigt werden. Ändern Sie das auf “alle Dateien”. Wählen Sie die CSV-Datei aus. Es erscheint der “Import-Wizard”.
für Office 2019 und Office 365: Starten Sie Excel, und wählen Sie im Reiter “Daten” (tab “data”) die Funktion “Daten abrufen” (“Get Data”) unnd dort “Aus Text/CSV” (“From Text/CSV”). Dann sollte der “Import Wizard” erscheinen.
(Da ich gerade kein aktuelles Excel zur Hand habe, habe ich ChatGPT gefragt, wie die Optionen beschriftet sind. Geben Sie mir bitte Bescheid, falls ChatGPT falsch liegt.)
Ändern Sie etwas an der Tabelle, und speichern Sie sie im CSV-Format.Dazu brauchen Sie die Funktion “Speichern unter” (“Save as”), denn dort können Sie den “Dateityp” (“type”) auf “CSV” schalten. In neueren Excel-Versionen können Sie noch das Encoding auswählen. Wählen Sie hier “UTF-8”. (Das ist nur wichtig, wenn Sie Umlaute o.ä. im Text haben.)
Laden Sie die geänderte CSV-Datei in R. Ist die Änderung angekommen?
Forum
Wenn Sie Schwierigkeiten mit den Aufgaben haben, stellen Sie eine Frage auf dem Moodle-Forum.
Abgabe auf Moodle
Stellen Sie Code, Plots und Antworten für die Aufgaben 1 bis 3 zusammen (z.B. in einer Word-Datei) und laden Sie ein PDF auf Moodle hoch. (Wenn Sie Word verwenden, benutzen Sie zu Darstellung von Code bitte eine Monospace-Font wie z.B. Courier.)
Das Kopieren von Code und Ergebnissen von RStudio zu Word ist mühsam und fehleranfällig. Wir werden bald lernen, wie man PDFs bequem direkt in RStudio erzeugt, mit “Quarto Documents” oder “R Notebooks”. Wenn Sie wollen, können Sie RStudio’s Quarto-Funktionalität aber schon jetzt ausprobieren.