── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
read_csv( "Downloads/nhanes.csv" ) -> nhanes
Rows: 8704 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): gender, ethnicity
dbl (4): subjectId, age, height, weight
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
nhanes
# A tibble: 8,704 × 6
subjectId gender age height weight ethnicity
<dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 93703 female 2 88.6 13.7 NH Asian
2 93704 male 2 94.2 13.9 NH White
3 93705 female 66 158. 79.5 NH Black
4 93706 male 18 176. 66.3 NH Asian
5 93707 male 13 158. 45.4 Other/Mixed
6 93708 female 66 150. 53.5 NH Asian
7 93709 female 75 151. 88.8 NH Black
8 93710 female 0 NA 10.2 NH White
9 93711 male 56 171. 62.1 NH Asian
10 93712 male 18 173. 58.9 Mexican
# ℹ 8,694 more rows
Heute lernen wir, wie man “summerizing functions” auf Tabellen anwendet. Wichtiger Zweck solcher Funktionen ist die Erstellungs beschreibender Statistiken (descriptive statistics) wie z.B. Mittelwert, Median, etc.
Zur Erinnerung: Eine summerizing function fasst einen Vektor mit vielen Zahlen (z.B. eine Tabellen-Spalte) zu einer Zahl zusammen.
Beispiele: Mittelwert (mean), Summe (sum), Median (median), Varianz (var), Standardabweichung (sd), aber auch Maximum (max), Minimum (min), Anzahl der Werte (length, oder, nur in Tidyverse, n), uvm.
Unsere Aufgabe: Berechne die mittlere Körpergröße der erwachsenen Frauen und Männer.
NA-Filtern
Eigentlich können wir das mit dem Gelernten schon lösen:
Wir erstellen erst eine Tabelle aller erwachsenen Männer:
nhanes %>%filter( gender =="male", age >=18 ) -> nhanes_adult_mennhanes_adult_men
# A tibble: 2,672 × 6
subjectId gender age height weight ethnicity
<dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 93706 male 18 176. 66.3 NH Asian
2 93711 male 56 171. 62.1 NH Asian
3 93712 male 18 173. 58.9 Mexican
4 93713 male 67 179. 74.9 NH White
5 93715 male 71 171. 65.6 Other/Mixed
6 93716 male 61 159. 77.7 NH Asian
7 93717 male 22 174. 74.4 NH White
8 93718 male 45 157. 54.4 NH Black
9 93723 male 64 170. 64.9 NH White
10 93727 male 70 162. 62.7 NH Asian
# ℹ 2,662 more rows
Nun können wir mean auf die Spalte anwenden:
mean( nhanes$height )
[1] NA
Warum hat das nicht geklappt? Anscheinend fehlt bei ein paar Männern die Angabe der Größe.
Wir können mean anweisen, diese fehlenden Werte (die in der Tabelle mit NA, für not available, merkiert sind) zu überspringen, indem wir das Zusatz-Argument na.rm (für NA removal) angeben:
mean( nhanes$height, na.rm=TRUE )
[1] 156.5934
Eine andere Lösung ist, unseren Filter zu erweitern, um die störenden Zeilen aus der Tabelle ganz zu entfernen:
nhanes %>%filter( gender =="male", age >=18, !is.na(height) ) -> nhanes_adult_mennhanes_adult_men
# A tibble: 2,630 × 6
subjectId gender age height weight ethnicity
<dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 93706 male 18 176. 66.3 NH Asian
2 93711 male 56 171. 62.1 NH Asian
3 93712 male 18 173. 58.9 Mexican
4 93713 male 67 179. 74.9 NH White
5 93715 male 71 171. 65.6 Other/Mixed
6 93716 male 61 159. 77.7 NH Asian
7 93717 male 22 174. 74.4 NH White
8 93718 male 45 157. 54.4 NH Black
9 93723 male 64 170. 64.9 NH White
10 93727 male 70 162. 62.7 NH Asian
# ℹ 2,620 more rows
Nun haben wir in filter drei Filter-Kriterien: männlich; erwachsen; mit Angabe der Körpergröße.
Der dritte Filter funktioniert so: Die Funktion is.na prüft, ob der Wert NA (not available) ist:
is.na( c( 2, 3, NA, 6, 5, NA, 7 ) )
[1] FALSE FALSE TRUE FALSE FALSE TRUE FALSE
Da filter die Zeilen behält, bei denen die Bedingung wahr (TRUE) ist, müssem wir die Wahrheitswerte invertieren, mit dem Ausrufezeichen, das als “Nicht-Operator” (not operator) wirkt:
Das Tidyverse-Verb summarise (oder summarize) erlaubt es, summerizing functions in einer Tidyverse-Pipeline einzubauen. Man erhält dann eine Tabelle mit nur einer Zeile.
Man kann auch mehrere Summarisierungen durchführen:
Das group_by( gender ) hat die Zeilend er Tabelle in zwei Gruppen eingeteilt, gemäß dem Inhalt der Spalte gender, die entweder male oder female enthält.
Das nachfolgende summerise führt dann die Sumamrisierung für jede Gruppe getrennt durch. Die erzeugt Tabelle enthält dann eine Zeile pro Gruppe.
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
# A tibble: 12 × 5
# Groups: gender [2]
gender ethnicity `mean(height)` `min(height)` `max(height)`
<chr> <chr> <dbl> <dbl> <dbl>
1 female Mexican 157. 138. 181.
2 female NH Asian 156. 140. 177.
3 female NH Black 162. 139 188.
4 female NH White 161. 141. 189.
5 female Other Hispanic 157. 140. 182.
6 female Other/Mixed 162. 147. 175.
7 male Mexican 170. 148. 192.
8 male NH Asian 170. 152. 188
9 male NH Black 176. 153. 198.
10 male NH White 175. 152. 196.
11 male Other Hispanic 169. 148. 187
12 male Other/Mixed 176. 158. 195.
Nun haben wir 12 Gruppen (2 Geschlechter x 6 Ethnien) und entsprechend 12 Zeilen in der Ausgabe von summarize. Die Ausgabe hat 5 Zeilen, nämlich
zwei Spalten mit den Gruppen-Labels, die in group_by angegeben wurden (gender, ethnicity)
drei Spalten mit Ergebnissen der drei Summarisierungs-Operationen, die in summerize angegeben wurden
Merke:group_by und summarize werden meist zusammen verwendet. Ersteres teilt die Zeilen in Gruppen ein, letzteres fasst die Zeilen jeder Gruppe zu einer einzelnen Zeile zusammen.
Zählen in Gruppen
Der Mittelwert (mean) ist eine einfache Statistik; die Anzahl der Zeilen (n) eine noch einfachere.
Wir verwenden dies, um zu unsere Frage zurück zu kommen, welcher Prozentsatz der Frauen und Männer übergewichtig bzw. adipös ist.
Aufgabe: Erstellen Sie dafür eine Tabelle wir folgt:
Beginnen Sie mit der nhanes-Tabelle
Filtern Sie, dass nur die Erwachsenen Probanden/Probandinnen verbleiben
Fügen Sie eine Spalte mit dem BMI hinzu (wie zuvor)
Fügen Sie eine Spalte obese hinzu, die angibt, ob die person adipös ist, d.h., einen BMI über 30 hat:
So soltle die Tabelle aussehen:
# A tibble: 5,533 × 8
subjectId gender age height weight ethnicity bmi obese
<dbl> <chr> <dbl> <dbl> <dbl> <chr> <dbl> <lgl>
1 93705 female 66 158. 79.5 NH Black 31.7 TRUE
2 93706 male 18 176. 66.3 NH Asian 21.5 FALSE
3 93708 female 66 150. 53.5 NH Asian 23.7 FALSE
4 93709 female 75 151. 88.8 NH Black 38.9 TRUE
5 93711 male 56 171. 62.1 NH Asian 21.3 FALSE
6 93712 male 18 173. 58.9 Mexican 19.7 FALSE
7 93713 male 67 179. 74.9 NH White 23.5 FALSE
8 93714 female 54 148. 87.1 NH Black 39.9 TRUE
9 93715 male 71 171. 65.6 Other/Mixed 22.5 FALSE
10 93716 male 61 159. 77.7 NH Asian 30.7 TRUE
# ℹ 5,523 more rows
Aufgabe: Teilen Sie die Tabellenzeilen nun mit group_by in vier Gruppen ein, nämlich gemäß dem Geschlecht (male/female) und nach dem Adipositas-Status (obese TRUE/FALSE). Lassen Sie dann mit summerize für jede Gruppe die Summarisierungs-Operation n() ausführen, die einfach zählt, wie viele Zeilen in der Gruppe sind.
Werte wie Größe und Gewicht sind kontinuierlich (“continuous”), d.h., es gibt beliebige Zwischenwerte.
Werte wie Geschlecht und Ethnie sind kategorisch (“categorical”): Es gibt eine vorgegebene Liste von Werten (z.B. “male” und “female”) und andere als diese sind nicht möglich. Manchmal spricht man auch von “diskreten” Werten.
Bei kategorischen Werten macht es oft Sinn, nicht jedesmal das Wort (“male” oder “female”) anzugeben, sondern einfach einen Code (eine Zahl) zu speichern, zusammen mit einer Kodierungstabelle (z.B. 1=“male”, 2=“female”). Einen auf diese Art angelegten Vektor nennt man in R einen “Faktor” (factor), die möglichen Werte nennt man Levels.
Diskretisierung
Oft macht es Sinn, kontinuierliche Werte anhand eines Rasters aus Grenzen zu diskretisieren.
Beispiel 1: Beim Histogramm bildet R den Wertebereich auf ein Raster von “Bins” (Eimern) ab, und ordnet jeden Wert in eine Bin, die dann als ein Balken im Diagramm dargestellt wird.
Beispiel 2: Die WHO schlägt vor, BMI-Werte wie folgt zu interpretieren:
unter 18.5: untergewichtig
18.5 bis 25: normal
25 - 30: übergewichtig
über 30: adipös
Die R-Funktion cut ermöglicht uns, die BMI-Werte entlang dieser Grenzen zu diskretisieren.
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
# A tibble: 8 × 3
# Groups: gender [2]
gender weight_state n
<chr> <fct> <int>
1 female underweight 57
2 female normal 743
3 female overweight 795
4 female obese 1216
5 male underweight 43
6 male normal 639
7 male overweight 930
8 male obese 1011
Hier haben wir bei summarise einen Spaltennamen angegeben, nämlich n (statt bisher n()), indem wir den gewünschten Spaltennamen, gefolgt von einem =, vor die Summarisierungs-Operation gesetzt haben.
Nun möchten wir die diese Tabelle noch um eine Spalte mit Prozenten ergänzen:
`summarise()` has grouped output by 'gender'. You can override using the
`.groups` argument.
# A tibble: 8 × 4
# Groups: gender [2]
gender weight_state n percent
<chr> <fct> <int> <dbl>
1 female underweight 57 2.03
2 female normal 743 26.4
3 female overweight 795 28.3
4 female obese 1216 43.3
5 male underweight 43 1.64
6 male normal 639 24.4
7 male overweight 930 35.5
8 male obese 1011 38.5
Wie funktioniert dies?
Das zweite group_by teilt die 8 Zeilen in zwei Gruppen (male, female) zu je 4 Zeilen ein.
Das nachfolgende mutate wird für jede Gruppe getrennt durchgeführt. Daher ergibt sum(n) die Summe der Spalte nnur über die Zeilen der Gruppe. Jedes n wird also durch die Summe der vier n-Werte des jeweiligen Geschlechts geteilt. Somit addieren sich die Geschlechter jeweils getrennt zu 100%.
Hausaufgabe
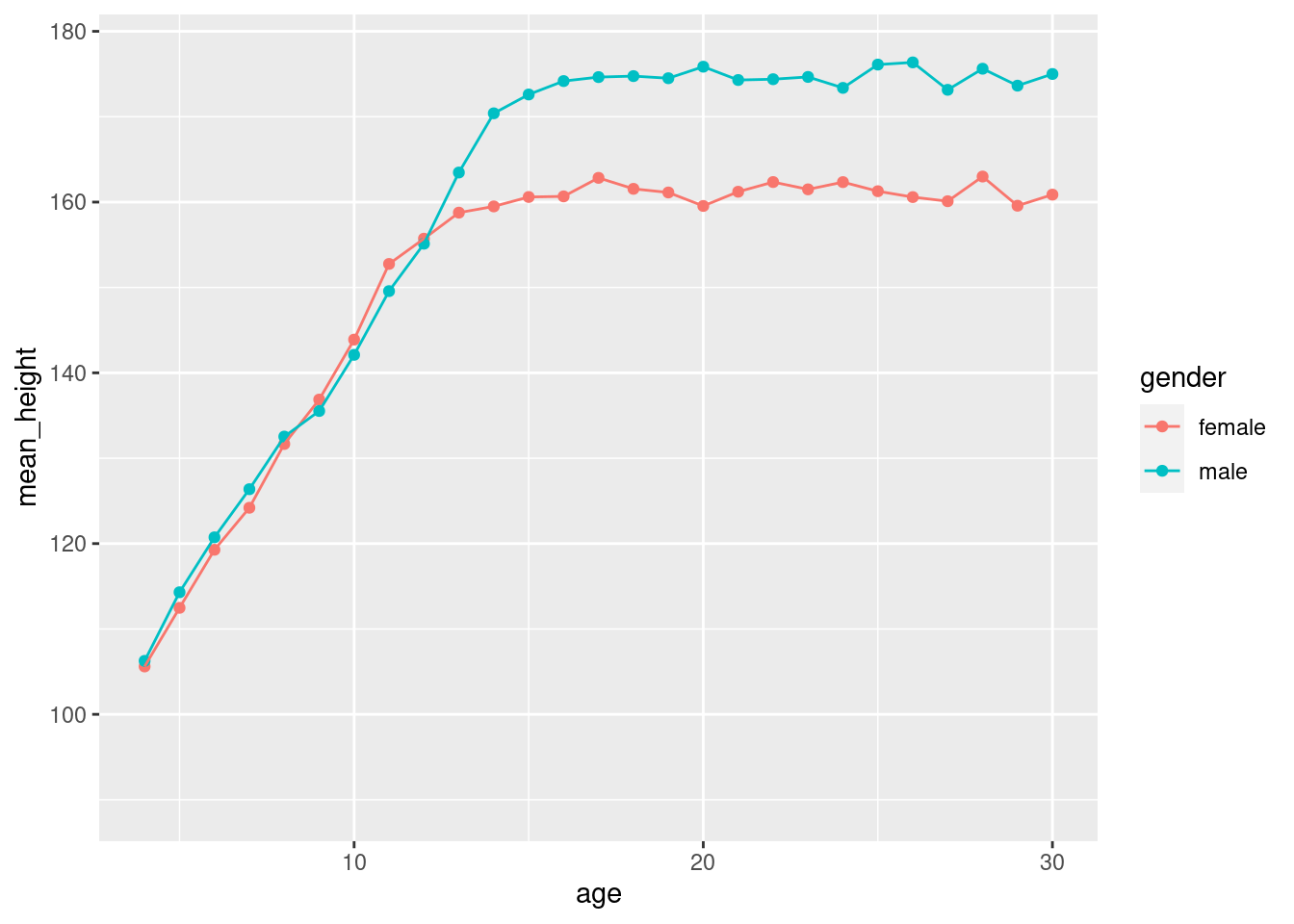
Hier ist ein Plot mit der Durschschnitts-Größe der Probanden jedes Jahrgangs, aufgeschlüsselt nach Geschlecht:
`summarise()` has grouped output by 'age'. You can override using the `.groups`
argument.
Bauen Sie dazu eine Tidyverse-Pipeline, die die folgenden Schritte durchführt:
Beginnen Sie mit der NHANES-Tabelle
Entfernen Sie alle Tabellen-Zeilen, bei denen die Körpergröße fehlt (d.h., als NA markiert ist)
Gruppieren sie die Tabelle mit group_by, so dass jede Gruppe jeweils Zeilen enthält, die das selbe Geschlecht und dasselbe Lebensalter in Jahren aufweist. Da die Alters-Zahlen von 4 bis 80 gehen (also 77 verschiedene Werte), soltlen Sie 2x77=158 Gruppen erhalten.
Berechnen Sie für jede Gruppe den mittelwert von height und nennen Sie diese neue Spalte mean_height. Nun sollle Ihre Tabelle so aussehen:
Geben Sie diese Tabelle an `gplot weiter. Legen Sie per aes fest, aus welchen Spalten für x, y und color entnommen werden sollen.
Als Geom können Sie geom_point verwenden, um ein Streudiagramm (scatter plot) zu erhalten. Wenn Sie als zweites Geom noch geom_line hinzu addieren, werden die Punkte durch Linien verbunden.
Mit xlim können Sie in die x-Achse “hinein zoomen”, so dass man die Jahre, in denen die Probanden noch nicht ausgewachsen sind, besser sehen kann.
Intepretieren Sie den Plot:
Wie entsteht der Unterschied zwischen Frauen und Männern aus? Wann sind Jungen und Mädchen ausgewachsen>?
Wann sind Jungen größer und wann Mädchen? Glauben Sie, dass es unter 13 Jahren einen Unterschied gibt?
Facetting:
Können Sie den Plot so erweitern, dass Sie einen Plot pro Ethnie haben? Benutzen Sie facet_grid.
Laden Sie Ihren Plot und Ihren Code bitte auf Moodle hoch.