R ist alt: Die erste Version wurde 1993 veröffentlicht, und war anfangs eine “Kopie” von S, das seit 1976 entwickelt wurde. Viele Konstrukte sind daher schon lange nicht mehr “state of the art”. Andererseits wurde R immer wieder modernisiert, und es wurden neue, bequemer zu benutzende Funktionen eingeführt, um ältere, umständlichere oder weniger leistungsfähige Funktionen und Pakete zu ersetzen – ohne aber die alten Funktionen zu entfernen. Wenn man R-Code verstehen will, hilft es daher oft, zu wissen, in welcher “geschichtlichen Schicht” man sich bewegt.
Tidyverse
Die “aktuelle Schicht” ist das “Tidyverse”, entwickelt von Hadley Wickham, seit ca. 2014 und weit verwendet seit ca. 2017.
“Tidyverse” ist ein Versuch, das “unordentlich” gewordene “Universum” der vielen R-Funktionen aus verschiedenen Zeiten zu ersetzen. “Tidyverse” besteht aus einer Reihe von Paketen, die einer einheitlichen und logischen Design-Philosophie folgen.
Zentraler Datentyp in Tidyverse ist die Tabelle, die aber oft nicht (wie in “base R”) Data Frame genannt wird, sondern “tibble” (Kunstwort für “tidy table”).
Das Buch “R for Data Science” (“r4ds”) dient als Lehrbuch zur Datenanalyse mit R und Tidyverse.
Wir werden von nun an so weit wie möglich nur Tidyverse verwenden.
Um Tidyverse zu verwenden, muss es stets erst geladen werden:
library( tidyverse )
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
NHANES
Als Beispieldaten werden wir in der Vorlesung oft Ergebnisse der NHANES-Studie des CDC nutzen. NHANES führt alle 2 Jahre eine Erhebung zur VOlksgesundheit durch, bei der eine repräsentante Stichprobe von knapp 10,000 Einwohnern der USA befragt und medizinisch untersucht werden. Näheres hier: https://www.cdc.gov/nchs/nhanes
Wir verwenden den Durchgang 2017/18 (“J”), spezifisch die Tabellen “DEMO_J” und “BMX_J” mit demoghraphischen Daten und den Körpermaßen (Body Measures) der Probanden.
Ich habe einige Spalten ausgewählt und zusammengestellt in dieser Tabelle: https://papagei.bioquant.uni-heidelberg.de/simon/Vl2021/nhanes.csv
Wir laden diese Datei mit der Tidyverse-Fuktion read_csv:
nhanes <-read_csv( "Downloads/nhanes.csv")
Rows: 8704 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): gender, ethnicity
dbl (4): subjectId, age, height, weight
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Wir sehen uns die Tabelle an:
nhanes
# A tibble: 8,704 × 6
subjectId gender age height weight ethnicity
<dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 93703 female 2 88.6 13.7 NH Asian
2 93704 male 2 94.2 13.9 NH White
3 93705 female 66 158. 79.5 NH Black
4 93706 male 18 176. 66.3 NH Asian
5 93707 male 13 158. 45.4 Other/Mixed
6 93708 female 66 150. 53.5 NH Asian
7 93709 female 75 151. 88.8 NH Black
8 93710 female 0 NA 10.2 NH White
9 93711 male 56 171. 62.1 NH Asian
10 93712 male 18 173. 58.9 Mexican
# ℹ 8,694 more rows
Eine Erklärung der Spalten findet sich hier: https://wwwn.cdc.gov/Nchs/Nhanes/2017-2018/BMX_J.htm
Aufgabe
Laden Sie die Tabelle vom o.g. Link herunter und laden Sie sie in Ihre R-Sitzung. Lassen Sie sich die Tabelle in RStudio anzeigen.
Tidyverse-Verb “mutate”
In Tidyverse wandelt jeder ARbeitsschritt eine Tabelle in eine andere Tabelle um. Zu jedem Schritt gehört ein “Tidyverse-Verb”, d.h. eine Funktion, die eine Tibble als erstes Argument verlangt und eine abgeänderte Tibble zurückgibt.
Das Tidyverse-Verb mutate ändert eine Spalte ab oder fügt eine neue Spalte hinzu.
BMI
Wir möchten der Tabelle eine Spalte bmi mit dem Body Mass Index (BMI) hinzufügen. Der BMI ist wie folgt definiert:
\[ \text{BMI}=\frac{\text{Körpergewicht in kg}}{\text{(Körpergröße in m)}^2}. \] Unsere Tabelle enthält die Größe in cm, daher müssen wir durch 100 teilen.
Wir schreiben also:
mutate( nhanes, bmi = weight / (height/100)^2 )
# A tibble: 8,704 × 7
subjectId gender age height weight ethnicity bmi
<dbl> <chr> <dbl> <dbl> <dbl> <chr> <dbl>
1 93703 female 2 88.6 13.7 NH Asian 17.5
2 93704 male 2 94.2 13.9 NH White 15.7
3 93705 female 66 158. 79.5 NH Black 31.7
4 93706 male 18 176. 66.3 NH Asian 21.5
5 93707 male 13 158. 45.4 Other/Mixed 18.1
6 93708 female 66 150. 53.5 NH Asian 23.7
7 93709 female 75 151. 88.8 NH Black 38.9
8 93710 female 0 NA 10.2 NH White NA
9 93711 male 56 171. 62.1 NH Asian 21.3
10 93712 male 18 173. 58.9 Mexican 19.7
# ℹ 8,694 more rows
Piping
Den vorstehenden Befehl kann man auch so schreiben:
nhanes %>%mutate( bmi = weight / (height/100)^2 )
# A tibble: 8,704 × 7
subjectId gender age height weight ethnicity bmi
<dbl> <chr> <dbl> <dbl> <dbl> <chr> <dbl>
1 93703 female 2 88.6 13.7 NH Asian 17.5
2 93704 male 2 94.2 13.9 NH White 15.7
3 93705 female 66 158. 79.5 NH Black 31.7
4 93706 male 18 176. 66.3 NH Asian 21.5
5 93707 male 13 158. 45.4 Other/Mixed 18.1
6 93708 female 66 150. 53.5 NH Asian 23.7
7 93709 female 75 151. 88.8 NH Black 38.9
8 93710 female 0 NA 10.2 NH White NA
9 93711 male 56 171. 62.1 NH Asian 21.3
10 93712 male 18 173. 58.9 Mexican 19.7
# ℹ 8,694 more rows
Das Pipe-Zeichen %>% bedeutet hierbei: Nimm die Daten links vom Pfeil und füge sie in dem Funktionsaufruf rechts vom Pfeil als erstes Argument ein.
Tidyverse-Verb “filter”
Die Tabelle hat 8704 Zeilen, enthält also Daten von 8704 Probanden. Wie viele davon sind erwachen, also min. 18 Jahre alt? Mit der tidyverse-Funktion filter können wir die Tabelle filtern, d.h. nur die Zeilen behalten, die eine gegebene Bedingung erfüllen, hier: Alter mindestens 18 Jahre.
nhanes %>%filter( age >=18 )
# A tibble: 5,533 × 6
subjectId gender age height weight ethnicity
<dbl> <chr> <dbl> <dbl> <dbl> <chr>
1 93705 female 66 158. 79.5 NH Black
2 93706 male 18 176. 66.3 NH Asian
3 93708 female 66 150. 53.5 NH Asian
4 93709 female 75 151. 88.8 NH Black
5 93711 male 56 171. 62.1 NH Asian
6 93712 male 18 173. 58.9 Mexican
7 93713 male 67 179. 74.9 NH White
8 93714 female 54 148. 87.1 NH Black
9 93715 male 71 171. 65.6 Other/Mixed
10 93716 male 61 159. 77.7 NH Asian
# ℹ 5,523 more rows
Die gefilterte Tabelle hat noch 5533 Zeilen. Der Anteil Erwachsener an der Gesamtzahl von Probanden beträgt also in Prozent:
5533/8704*100
[1] 63.56847
Eine einfache Pipeline
Nun können wir fragen, wie viele dieser 5366 Erwachsenen übergewichtig sind. Wir verwenden hierzu die WHO-Definition, die Übergewicht als BMI>25 definiert.
# A tibble: 3,952 × 7
subjectId gender age height weight ethnicity bmi
<dbl> <chr> <dbl> <dbl> <dbl> <chr> <dbl>
1 93705 female 66 158. 79.5 NH Black 31.7
2 93709 female 75 151. 88.8 NH Black 38.9
3 93714 female 54 148. 87.1 NH Black 39.9
4 93716 male 61 159. 77.7 NH Asian 30.7
5 93721 female 60 154 85.1 Mexican 35.9
6 93726 female 67 154. 74.3 Mexican 31.1
7 93728 male 53 188. 118. NH Black 33.4
8 93729 male 42 173. 82.8 NH Black 27.6
9 93730 male 57 168. 80.2 Other Hispanic 28.6
10 93731 male 20 180. 89.2 Mexican 27.6
# ℹ 3,942 more rows
Hier habven wir nun eine kurze “Pipeline” gebaut, in der die Daten mit dem Pipe-Pfeil%>% durch drei Arbeitsschritte hindurch geschoben werden:
Wir beginnen mit der Tabelle, so wir sie geladen haben
Dann filtern wir, um nur die Erwachsenen zu behalten
Dann fügen wir die Spalte mit dem BMI hinzu
Zuletzt filtern wir nochmals, um nur die Übergewichtigen zu behalten
Nun hat die Tabelle noch 3952 Zeilen
Der Anteil Übergewichtiger unter den erwachsenen Probanden ist also
3952/5533
[1] 0.7142599
Zuweisen einer Tabelle zu einer Variable
Wir haben uns eine Tabelle aller Erwachsenen Probanden erstellt und diese durch eine BMI-Spalte ergänzt. Wir können diese modifizierte Tabelle wieder in eine neue Variable zurückschreiben, indem wir den Zuweisungs-Pfeil -> verwenden:
Merke: Wenn nichts anderes verlangt ist, gibt R das Ergebnis auf dem Bildschirm aus und verwirft es dann. Wenn man es behalten will, muss man es ausdrücklich eienr Variable zuweisen. Dann wird es aber nicht mehr ausgegeben. Um den Inhalt der Variablen auszugeben, gibt man einfach den Namen der Variablen ein und drückt Enter (oder Strg-Enter).
Aufgabe
Bei einem BMI über 30 spricht wird Übergewicht als Krankheit (Adipositas, Fettsucht, obesity) angesehen. Wie viele der Frauen und wie viele der Männer sind adipös? Berechnen Sie die Prozentsätze, indem Sie die Tabelle so filtern, dass Sie jeweils alle Männer, alle Frauen, alle adipösen Männer, alle adipösen Frauen erhalten, notieren Sie die Anzahl der Zeilen und berechnen Sie die Anteile in Prozent.
Plots mit ggplot
In R gibt es verschiedene Pakete, um Daten zu visualisieren. Wir werden “ggplot2” verwenden, dass wir Tidyverse von H. Wickham entwickelt wurde und nun Teil des Tidyverse ist.
Am Anfang steht eine Tabelle, entweder aus einer Variablen gelesen, oder mit einer Tidyverse-Pipeline erzeugt.
Diese wird mit dem Pipe-Pfeil %>% zur Funktion ggplot gesandt.
Die ggplot-Funktion hat ein Argument, das mit aes erzeugt wird.
Innerhalb des aes-Blocks wird festgelegt, aus welchen Tabellenspalten die Plot-Aspekte (z.B. x- und y-Koordinaten) entnommen werden sollen.
Darauf folgen ggplot-Komponenten, die mit + hinzugefügt werden und Details über den Plot spezifizieren.
Mindestens eine Koponente muss eine geom_-Funktion sein. Die Geoms wandeln Daten in Plot-Element um. Für jede Art von Plot gibt es ein zugehöriges Geom.
Neben geoms gibt es noch weitere Dinge, die man mit + hinzufügen kann.
In unserem Beispiel:
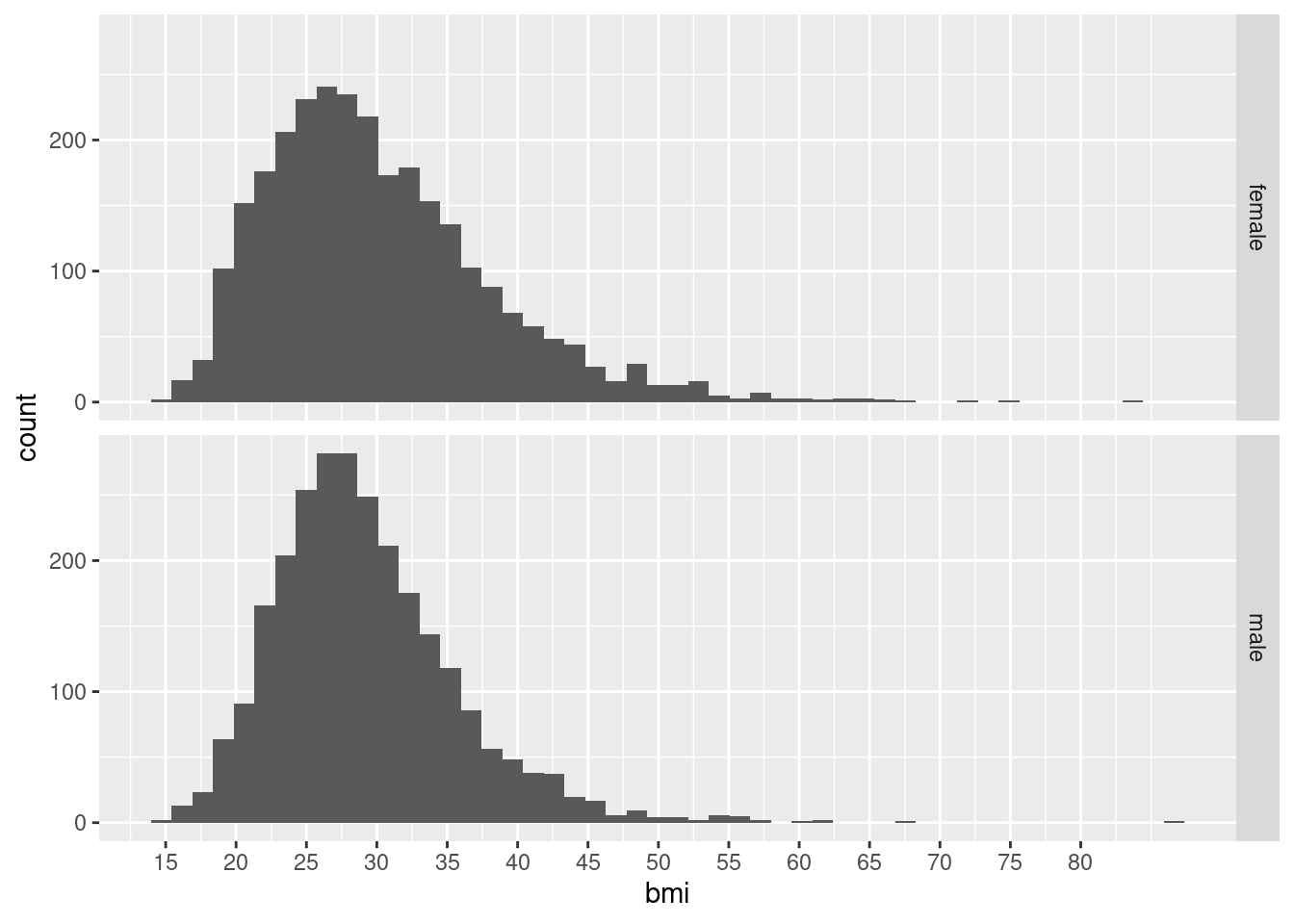
Wir möchten ein Histogramm, daher haben wir + geom_histogram geschrieben.
Für Histogramme brauch man nur eine aes-Spezifikation, nämlich, was die x-Achse sein soll. Wir haben x=bmi gewählt, d.h. die Tabellenspalte bmi soll durch die x-Achse repräsentiert werden.
Der Wertebereich der x-Achse soll in 50 “Bins” aufgeteilt werden.
Als Besonderheit haben wir Facetting verwendet:
Der Plot wird auf zwei Facets aufgeteilt, die untereinander (d.h. in zwei “rows” angeordnet sind).
Jede “row” ist für einen Teil der Daten zuständig, und zwar sollen die Daten gemäß der Spalte “gender” auf die Facet-Rows aufgeteilt werden.
Deshalb ist jede der beiden Rows am rechten rand mit einem der beiden Werte in “gender”, also “male” und “female” beschriftet.
Viele Arten von Plots
Die R Graph Gallery zeigt anhand vieler Beispiele, welche Art von Plots mit ggplot2 erzeugt werden können
Streudiagramme
Streudiagramme (engl. scatte plots) stellen jeden Datenpunkt (jede Tabellenzeile) durch einen Punkt dar. Da nun x- und y-Koordinate verfügbar sind, können wir zwei Tabellen-Zeilen gegeneinander auftragen. Die Farbe des Punktes können wir für eine dritte Spalte nutzen
Können Sie hier wieder die Elemente eines ggplot-Aufrufs sehen?
Das Geom geom_point erwartet zwwi Zuweisungen im aes-Block, nämlich x und y. Falls vorhanden, beachtet es auch noch weitere, z.B. colour.
Hausaufgaben
Experimentieren mit dem Histogramm
Betrachten Sie nochmal das Histogramm mit den BMI-Werten.
Vergleichen Sie die beiden Histogramme. Was können Sie über die Unterschiede zwischen Männern und Frauen in der Untersuchung ablesen?
Was geschieht, wenn Sie das + facet_grid(...) weglassen?
Was geschieht, wenn Sie + scale_x_continuous( breaks=seq( 15, 80, 5 ) ) anfügen?
Was geschieht, wenn Sie statt geom_histogram( bins = 50 ) einfach nur geom_histogram() schreiben?
Experimentieren Sie mit der Anzahl der Bins. Wie sieht das Histogramm mit nur 10 Bins, oder mit vielleicht 200 Bins aus? Was halten Sie für eine gute Anzahl?
Non-finite values
Vielleicht haben Sie bemerkt, dass R beim Zeichnen des Histogramms warnt: “Removed 99 rows containing non-finite values.” Sehen Sie sich die Tabelle an (z.B. in dem Sie sie in der Environment-Pane anklicken). Können Sie die 99 fehlerhaften Werte finden? Wo liegt das Problem?
Wenn Sie sie nicht finden: Schauen Sie sich z.B. den Probanden mit der SubjectID 93935 an. Können Sie mit filter diese Zeile aus der Tabelle isolieren?
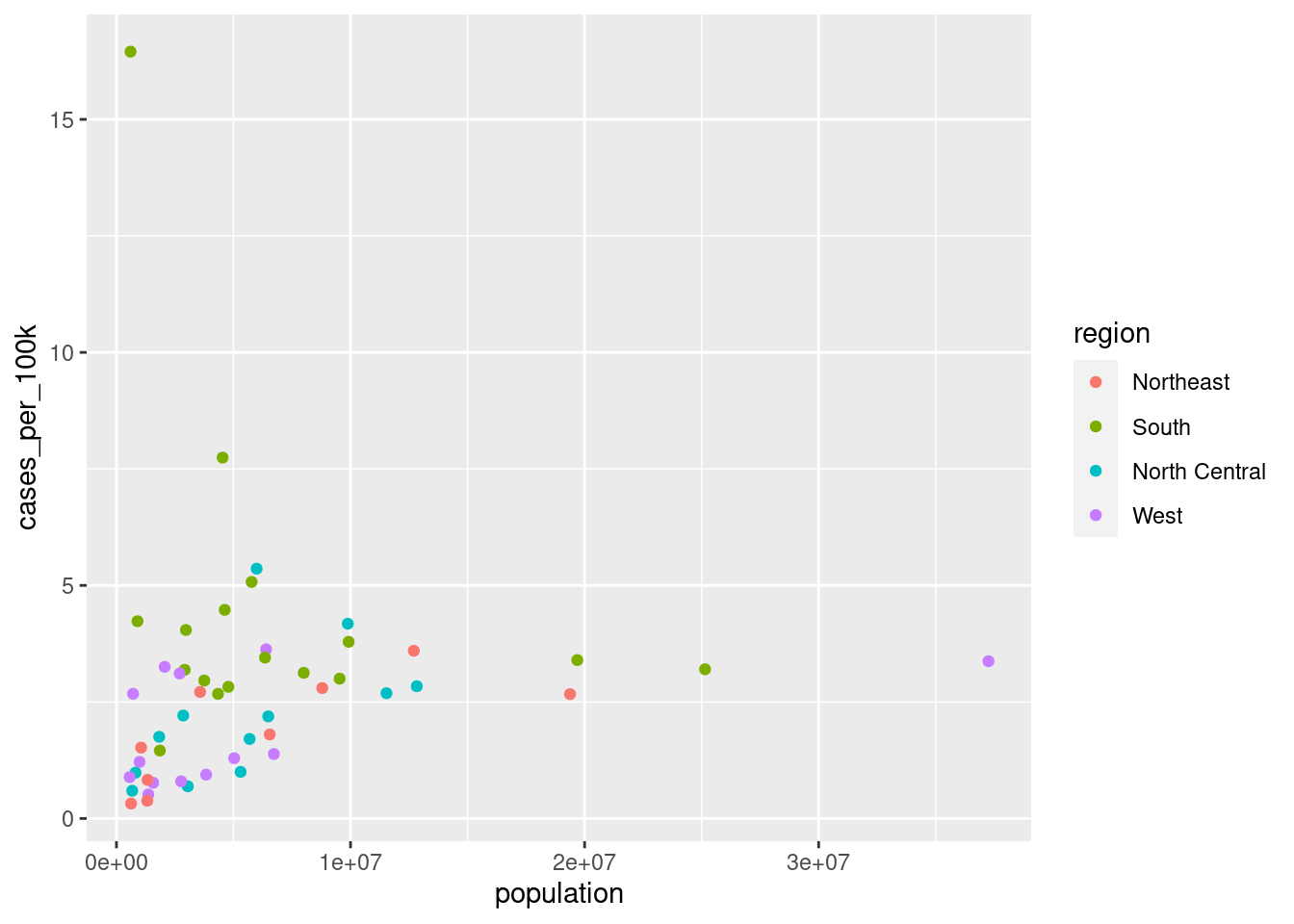
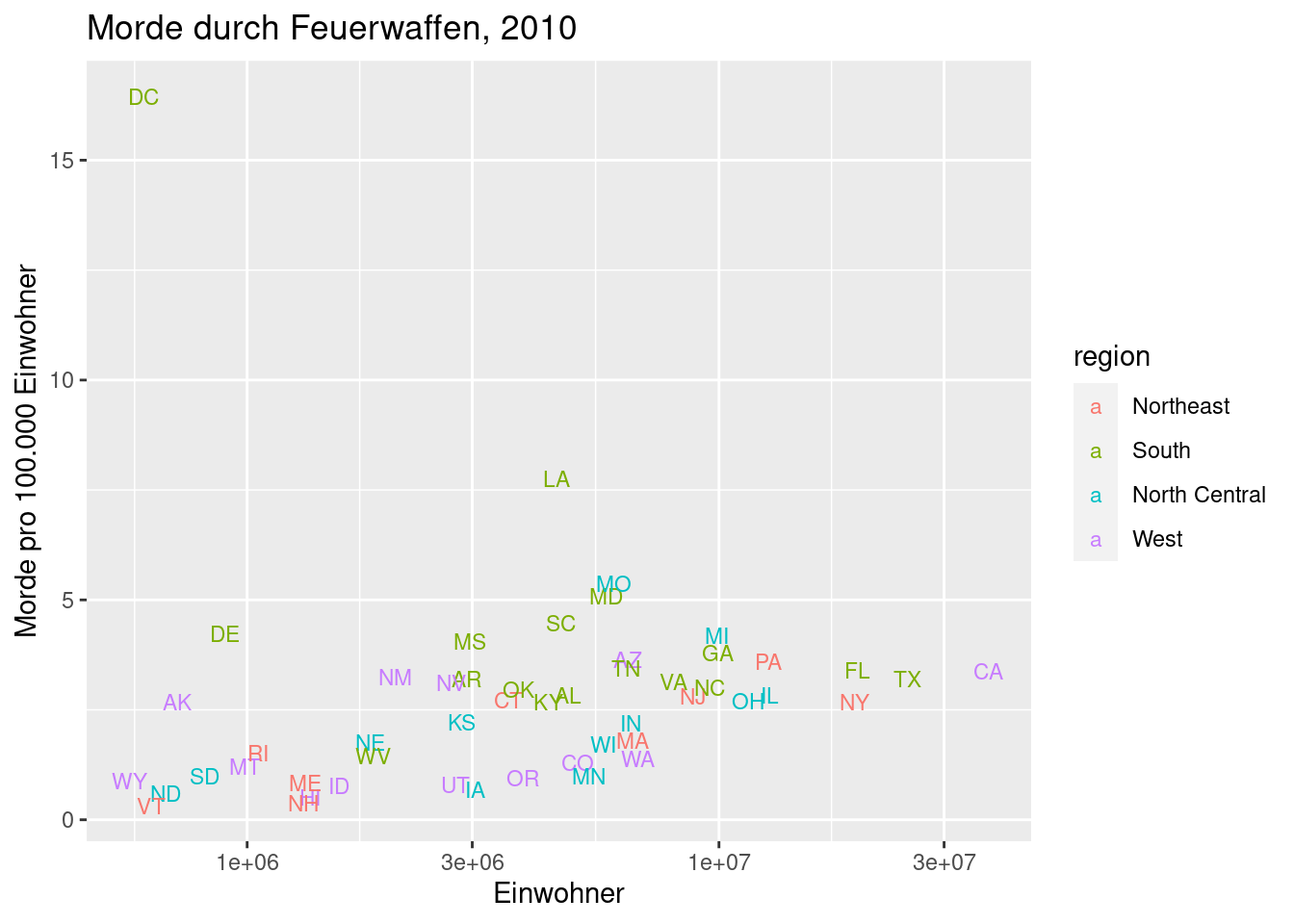
Noch ein Streudiagramm
Hier sehen Sie zwei Darstellung der Daten aus der murders-Tabelle vom Dienstag.
Zunächst ein einfaches Streudiagramm:
Nun eine verbesserte version desselben Plots:
Versuchen Sie zunächst, den ersten Plot selbst zu erzeugen.
Wenn Sie wollen, können Sie versuchen, den Plot zu verschönern, um zum zweiten Diagramm zu kommen:
Statt Punkten habe ich die Abkürzungen der Staaten verwendet (die in der Spalte abb stehen). Hierzu habe ich geom_point durch geom_text ersetzt. Letzteres erwartet neben x und y noch eine dritte aes-Angabe, nämlich label, d.h., die Spalte, aus der die Beschriftungen entnommen werden sollen.
Die Achsenbeschriftungen kann man mit ... + xlab( "Beschriftung" ) + ylab( "Bescriftung" ) ändern. Mit + ggtitle( "Beschriftung" ) legt man eine Überschrift fest.
Durch + scale_x_log10() macht man die x-Achse logarithmisch.
Sehen Sie, wie weit Sie kommen und laden Sie Ihren Plot auf Moodle hoch. Benutzen Sie dazu den “Export”-Button in der Plot-Pane, um Ihren Plot in eine Datei zu speichern, die Sie auf Moodle hoch laden können.