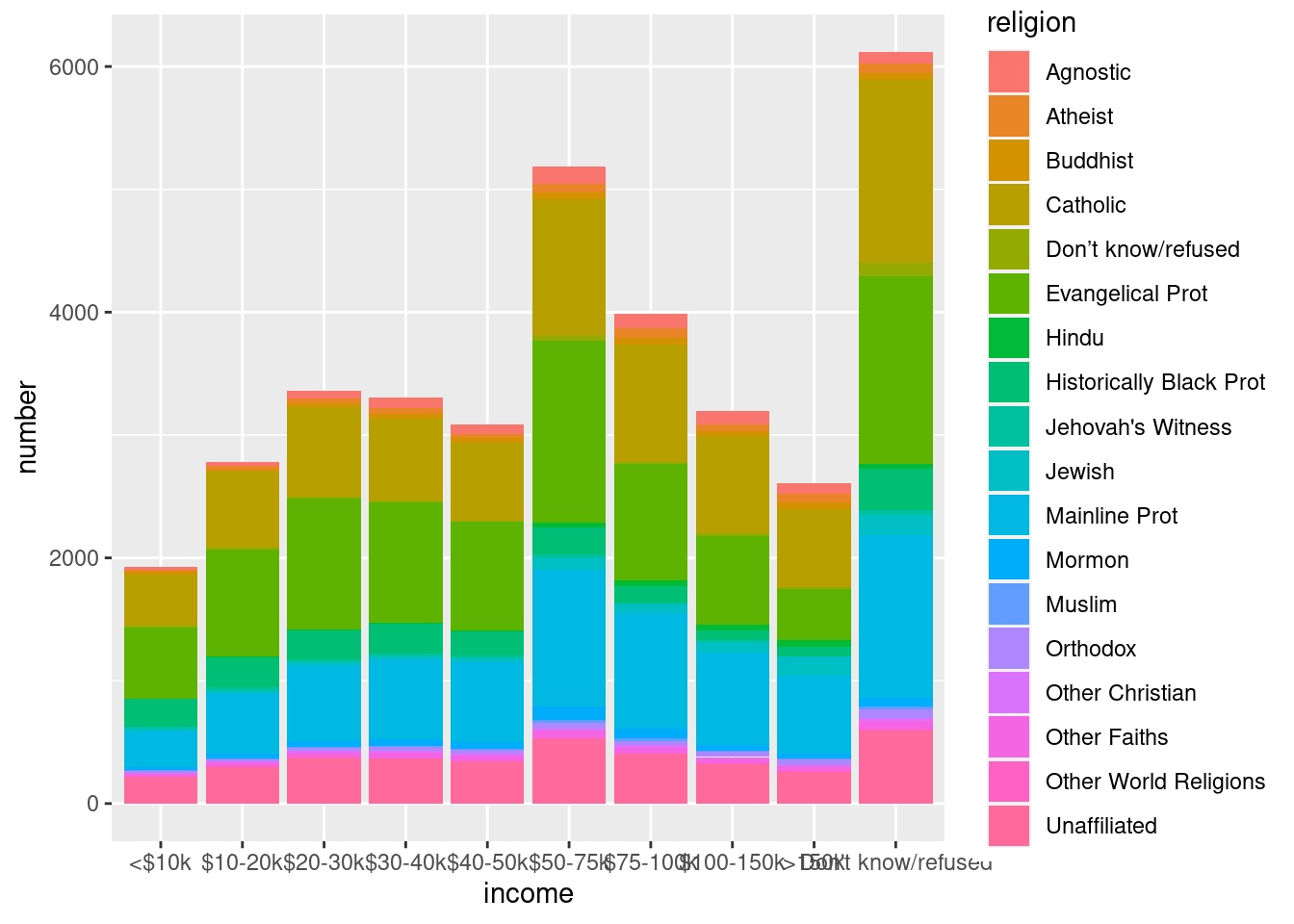
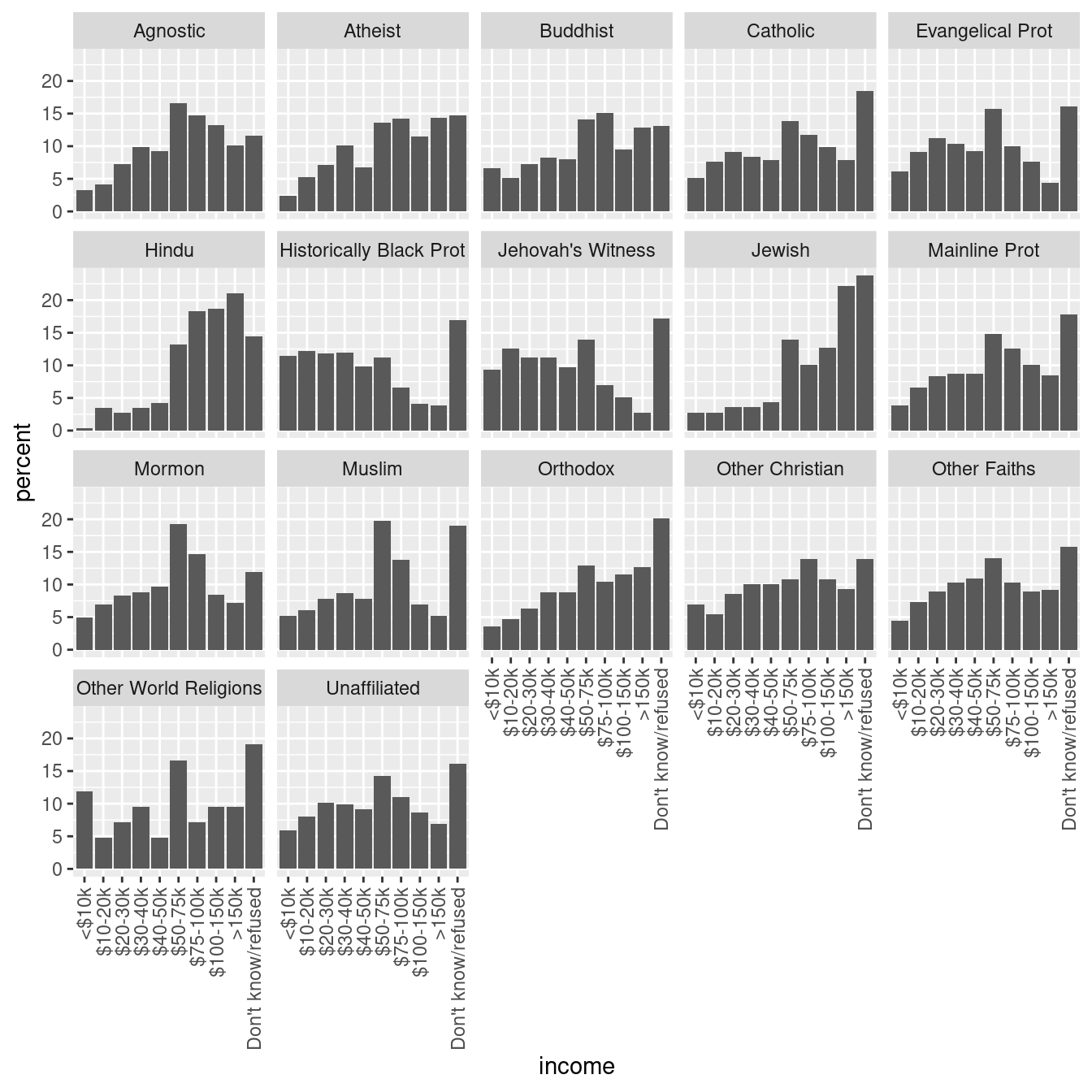
Im Tidyverse arbeitet man meist mit langen Tabellen, bei denen jede Zeile nur ein Objekt darstellt. Wickham, der Entwickler von Tidyverse, nennt olche Tabellen “tidy”.
In der Praxis hat man aber oft Tabellen, wo viele Daten nebeneinander stehen, weil diese übersichtlicher sind.
Beispieldaten
Mit dem Tidyverse-Paket mitgepackt ist folgende Tabelle mit Beispieldaten:
Wir möchten die Daten Plotten, aber dazu müssen wir die Tabelle “tidy” machen, d.h., diese “breite” Tabelle in eine “lange” umwandeln. Hierzu dient pivot_longer:
Eben haben wir für jede Religion berechnet, welche Anteil auf jede Einkommensklasse fällt:
Nun möchten wir diese Tabelle wieder in eine breite Tabelle zurück verwandeln, die nun statt der Anzahlen die Prozentwerte enthält, sonst aber genauso wie die ursprüngliche Tabelle aussieht.
Hierzu verwenden wir pivot_wider, die “Umkehrung” von pivot_longer
Hier hat pivot_wider die beiden angegebenen Spalten auf neue Spalten verteilt:
Für jeden Wert in der bei names_from angegebenen Spalte wurde eine Spalte mit dem entsprechenden Namen angelegt
Die unter id_cols angegebenen Spalten werden beibehalten, alle anderen Spalten entfernt.
Für alle Werte-Kombinationen, die in in den unter id_cols angebenen Spalten auftreten, wird eine Zeile angelegt. Deshalb haben wir nun eine Zeile pro Religion.
Die Werte aus der bei values_from angegebenen Spalte wurden dann auf die neuen Spalten verteilt, und zwar unter Beachtung der Einträge in der names_from-Spalte (die angibt in welche Spalte der Wert soll) und id_cols, die angibt in welche Zeile er soll.
Zusammenfassung
Die beiden pivot-Funktionen erlauben uns, Tabellen zwischen “breiten” und “langen” Anordnungen der Daten zu konvertieren.