Im vorigen Skript zur Binomialverteilung haben wir uns in einem “Hypothesentest-Setting” bewegt: Wir wollten wissen, ob der Würfel gezinkt ist oder nicht, oder ob die Segretation der Pflanzen Mendelsch ist oder nicht.
Wir hatten eine Nullhypothese, die eine bestimmte Erfolgswahrscheinlichkeit vorgab: 1/6 für eine Sechs bei einem ungezinkten Würfel, 1/4 für den rezessiven Phänotyp in der F2-Generation bei Mendelschem Erbgang – und wir fragten, ob die beobachteten Zahlen ausreichend Beweis waren, um die Nullhypothese abzulehnen.
Oft haben wir aber keinerlei “a priori”-Annahme zum erwarteten Anteil.
Wir möchten aus den Daten einen Anteil schätzen und wissen, wie genau die Schätzung wohl ist.
Beispiel: Welcher Anteil der erwachsenen Frauen in den NHANES-Daten sind übergewichtig (BMI>25)?
Der Anteil (proportion) übergewichtiger Probanden unter den Frauen beträgt also 28.46%:
2011/ (800+2011)
[1] 0.7154038
Wie genau ist dieser Wert? Um das zu beurteilen, brauchen wir ein Konfidenzintervall. Der p-Wert aus binom.test hilft nicht. Wir haben ja gar keine Nullhypothese.
Diese Unterscheidung, dass bei manchen Aufgaben das Konfidenzintervall, bei anderen der p-Wert gefragt ist, ist häufig und wichtig. In der Biologie wird dies leider oft nicht berücksichtig.
Standardfehler von Anteilen
Um der Frage nach dem Konfidenzintervall näher zu kommen, simulieren wir die NHANES-Erhebung.
Im Folgenden nehmen wir an, dass der wahre Anteil Übergewichtiger unter allen Frauen in den USA \(p=0.71\) betrage.
Simulieren wir uns nun eine Erhebung, in dem wir den BMI von \(n=1000\) Frauen bestimmen. Wie viele Übergewichtige finden wir?
Wie haben also 10000 mal die Anzahl der Übergewichtigen bestimmt, und jedes mal die Anzahl durch 1000 (der Umfang der simulierten Stichprobe) geteilt, um den Anteil zu erhalten. Wir sehen das Histogramm einer durch 1000 geteilten Binomialverteilung.
Was sind Erwartungswert und erwartete Standardabweichung dieser Verteilung?
Der Erwartungswert ist klar: Es ist \(\mu=p=0.71\).
Für die Standardabweichung überlegen wir: Wir sehen hier das Histogramm einer Binomialverteilung mit \(n=1000\) und \(p=0.71\). Deren Standardabweichung ist (gemäß der Formel von der vorigen Vorlesung): \(\sigma = \sqrt{n p (1-p)}\), also
n <-1000p <-0.71sqrt( n * p * (1-p) )
[1] 14.34922
Allerdings haben wir alle Werte durch \(n=1000\) geteilt, um die Anzahl Übergewichtiger in den Anteil Übergewichtiger umzurechnen. Die Stamdardabweichung im Histogramm sollte also sein: \(\sigma/n\), also
sef <-sqrt( n * p * (1-p) ) / nsef
[1] 0.01434922
Wir markieren das Intervall von Mittelwert minus eine Standardabweichung bis Mittelwert plus eine Standardabweichung im Histogramm:
hist( many_trials / n, breaks=100,main="30000 simulated trials", xlab="fraction of overweight subjects" )abline( v = p, col="orange" ) # Erwartungswert in orangeabline( v =c( p-sef, p+sef ), col="brown" ) # SD in braun
Das Histogramm ist durch eine Normalverteilung gut beschrieben (wie wir bereits in der vorigen Vorlesung gesehen haben). Nach der 68-95-99.5-Regel sollten 68% der Werte zwischen den braunen Linien liegen.
Wenn man einen Versuch, bei dem ein bestimmtes Ergebnis (“Erfolg”) mit eine unbekannten Wahrscheinlichkeit \(p\) auftritt, \(n\) mal wiederholt und die Anzahl \(k\) der Erfolge bestimmt, so ist der Anteil der Erfolge, \(\hat p=k/n\), ein geeigneter Schätzer für die Erfolgswahrscheinlichkeit.
Die Wahrscheinlichkeitsverteilung für diesen Schätzwert \(\hat p\) ist gegeben durch die Binomialverteilung \(\text{Binom(n,p)}\) geteilt durch \(n\). Ihr Erwartungswert ist daher der wahre Wert \(p\) und ihre Standardabweichung ist die Standardabweichung der Binomialverteilung, \(\sqrt{np(1-p)}\), geteilt durch \(n\), also: \[\text{SD}(\hat p)=\sqrt{\frac{p(1-p)}{n}}.\] Diesen Wert nennt man den Standardfehler des Anteils-Schätzers (standard error of the estimator of proportion).
Dies ist die Formel, die wir oben bereits verwendet haben (allerdings haben wir nun das \(n\) in der Wurzel gekürzt):
sqrt( p * (1-p) / n )
[1] 0.01434922
Ungenaues binomiales Konfidenzintervall
In unserem NHANES-Beispiel haben wir festgestellt, dass 2011 von insgesamt 2811 Frauen in der Stichprobe übergewichtig sind.
Wir schätzen also denn Anteil Übergewichtiger zu
k <-2011n <-2811frac <- k/n
Wenn wir dies für \(p\) in unsere Formel einsetzen, erhalten wir für den Standardfehler:
sef <-sqrt( frac * (1-frac) / n )sef
[1] 0.008510592
Wir können also nach der 68-95-99,7-Regel ein 68%-Konfidenzintervall bilden, indem wir den einfachen Standardfehler um den ermittelten Wert herum legen:
c( frac-sef, frac+sef )
[1] 0.7068932 0.7239144
und mit dem doppelten Standardfehler erhalten wir ein 95%-KI:
c( frac-sef, frac+sef )
[1] 0.7068932 0.7239144
Warum ist das ungenau?
Wie wir bereits letzte Vorlesung gesehen haben, ist die Normalverteilung keine gute Näherung füë die Binomialverteilung, wenn die Erfolgswahrscheinlichkeit sehr nahe an 0 oder 1 liegt (weil die verteilung dann sehr asymmetrisch wird), oder wenn der Stichprobenumfang \(n\) klein ist. Dann wird auch das eben erstellte einfache Konfidenzintervall schnell sehr ungenau.
Ein weiteres Problem entsteht daraus, dass wir die wahre Erfolgswahrscheinlichkeit \(p\) durch unsere Schätzung \(k/n\) ersetzen mussten, und dadurch der Standardfehler verfälscht wird.
Beispiel: Ein Würfel wird \(n=10\) mal geworfen, um die Wahrscheinlichkeit \(p\) zu ermitteln, eine Sechs zu würfeln. Das man keine einzige Sechs bei 10 Würfen erhält, ist gut möglich. Man schätzt dann \(\hat p = k/n = 0\), was nicht sonderlich weit vom wahren Wert \(p=0.167\) abweicht. Der exakte Standardfehler ist \(\sqrt{p(1-p)/n}=0.12\), was in Ordnung ist, aber wenn wir für \(p\) unsere Schätzung 0 einsetzen, erhalten wir Unsinn, nämlich einen Standardfehler von 0.
Agrestis Faustregel
Um das eben beschrieben Problem zu umgehen, schlägt der Statistiker Alain Agresti eine einfache Faustregel vor: “Add two successes and two failures”.
Wenn wir 0 Sechsen bei 10 Würfen erziehlt haben, rechnen wir also, als ob wir 2 Sechsen bei 14 Würfen erzielt hätten. Also:
Eine leicht verfeinerte Variante dieser Methode bietet die Funktion binom.agresti.coull aus dem Paket binom:
binom::binom.agresti.coull( 0, 10 )
method x n mean lower upper
1 agresti-coull 0 10 0 -0.04335451 0.3208873
Exaktes Konfidenzintervall
Auch Agrestis Methode berücksichtigt nicht die Asymmetrie der Binomialverteilung. Person und Clopper haben (im Jahr 1934) eine Methode angegeben, die ein KI ergibt, das exakt ist, in dem Sinn, das die Wahrscheinlichkeit, dass es den wahren Wert überdeckt, genau 95% ist (soweit dies trotz der Diskretheit der Binomialverteilung möglich ist).
Dazu haben sie die Logik des Binomialtests (siehe vorherige Vorlesung) umgedreht. Um die Obergrenze \(p_\text{u}\) eines 95%-KI für gegebene Werte von \(k\) und \(n\) zu erhalten, suchen Sie den Wert \(p_\text{u}\), für den folgendes gilt: Wenn man einen einseitigen Binomialtest durchführt, mit der Nullhypothese, dass die Erfolgswahrscheinlichkeit \(p_\text{u}\) beträgt und der Alternativehypothese, dass sie kleiner ist, dann ist der p-Wert des Tests genau 2,5%. Die Untergrenze wird aufdemselben Weg gefunden, nur das die Alternativhypothese für den Test dann ist, dass der wahre Wert größer als der Grenzwert ist.
Mit dieser Methode bekommen wir als 95%-Konfidenzintervall für unsere NHANES-Beobachtung:
binom::binom.exact( 2011, 800+2011 )
method x n mean lower upper
1 exact 2011 2811 0.7154038 0.6983271 0.7320308
Der Anteil Þbergweichtiger unter den erwachsenen Frauen in den USA betrug zur Zeit der NHANES-Erhebung also 71,5% mit 95%-KI von 69,8% bis 73,2%.
Bei einer so großen Stichprobe ist es egal, welche Methode wir verwenden. Sie ergeben alle fast dasselbe:
Wie Sie sehen, bietet das Paket noch einige weitere Methoden. Unsere Methode vom Anfang (mit dem Standardfehler) heißt hier asymptotic, die von Wilson-Clopper heißt exact und die von Agresti und Coull einfach agesti.coull.
Es gibt eine Vielzahl an Papern, die diskutieren, ob manche dieser Methoden nicht sogar besser als die “exakte” Methode wären.
Einfache Zusammenfassung
All diese Details brauchen Sie sich nicht merken. Für die Praxis verwenden Sie einfach die exakte Methode von Pearson und Clopper, wenn Sie einen Computer haben, und die von Agresti, wenn Sie schnell mit Papier und Bleistift arbeiten möchten.
Das binom-Paket mit den vielen Methoden brauchen Sie auch nichr. Die Funktion binom.test (siehe voriges Skript) kann nämlich auch exakte Pearson-Clopper-KIs berechnen:
binom.test( 2011, 800+2011 )
Exact binomial test
data: 2011 and 800 + 2011
number of successes = 2011, number of trials = 2811, p-value < 2.2e-16
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.6983271 0.7320308
sample estimates:
probability of success
0.7154038
Wir können hier das 95%-KI (nach Pearson-Clopper) ablesen.
Wir erhalten auch einen p-Wert. berechnet für die Nullhypothese, dass der wahre Anteil Übergewichtiger genau 1/2 ist (was R als Default-Wert verwendet hat, weil wir nichts angegeben haben) – aber diesen Wert ignorieren wir, da wir ja gar keinen Hypothesentest durchführen wollten.
Einschub: Pseudoreplikation
Wichtige Einschränkung: Bei der Berechnung der KIs für die NHANES-Daten haben wir angenommen, dass die Probanden alle unabhängig aus der Gesamtheit aller Einwohner der USA ausgewählt wurden (random sampling). Das ist aber nicht der Fall. Vielmehr wurde ein sog. zweistufiges Sampling-Verfahren verwendet, wo zunächst einie Orte zufällig ausgeählt wurden, und dann in jedem dieser Orte zufällig einige Probanden. Wir müssen aber erwarten, dass sich zwei Probanden aus demselben Ort ähnlicher sind als zwei Probanden die aus verschiedenen Orten stammen. Dadurch ist die Unsicherheit aller Schätzer größer als es unser Methoden hier feststellen. Das eben ermittelte KI für den Anteil Übergewichtiger ist also zu klein!
In dieser Vorlesung gehen wir stets von reinem random sampling aus, nehmen also an, dass jeder einzelne Proband unabhängig von den anderen aus der grundgesamtheit zufällig ausgewählt wurde. Alle Methoden, die wir hier besprechen, gelten nur unter dieser Annahme.
Wenn wir die NHANES-Daten als Beispiel verwenden, tun wir so, als ob NHANES nicht stratifiziert wäre. Eine korrekte Analyse der NHANES-Daten erfordert Berücksichtigung der Stufung; das führt aber über unsere Vorlesung hinaus.
In der Biologie tritt diese Problematik aber auch oft auf und wird hier “Pseudoreplikation” genannt. Daher werden wir später auf das Problem zurück kommen müssen.
Abhängigkeit der Genauigkeit vom Stichprobenumfang
Auch wenn die asymptotische Methode vom Beginn nicht genau ist, ist sie dennoch nützlich für Power-Calculations.
Die Formel für den Standardfehler (standard error, SE) eines geschätzten Anteils lautet (s.o.)
\[\text{SE}(\hat p) = \frac{\sqrt{p(1-p)}}{\sqrt{n}},\] wobei \(p\) die wahre Erfolgswahrscheinlichkeit und \(n\) die Anzahl der Versuche (Stichprobenumfang) ist.
Vergleichen Sie mit der Formel für den Standardfehler des Mittelwerts:
In beiden Fällen ist der Fehler proprtional zu \(1/\sqrt{n}\), die Genauigkeit steigt also proportional zur Quadratwurzel des Stichproben-Umfangs.
Beispiel für eine Power-Calculation
Betrachten wir wieder den Kreuzungsversuch von zuvor. Wir haben, wie einst Gregor Mendel, zwei Formen der Ebse, deren Samen entweder gelb oder grün sind. In der P-Generation liegen die beiden Formen in Reinzucht vor. Wir kreuzen sie und haben nun viele Samen der F1-Generation, die alle jeweils ein gelbsamiges und ein grünsamiges Elternteil haben. Für den Moment nehmen wir an, dass wir beliebig viele solcher F1-Pflanzen haben, die alle heterozygoten Genotyp haben, und die wir nun nochmals kreuzen können.
Nehmen wir an, das wahre Segregations-Verhältnis betrage nicht 1:3, sondern etwas kleiner: Wir erhalten also nicht 25% Nachkommen mit gelben (rezessiven) Samen, sondern nur 22%, weil die Samenfarbe nicht von einem, sondern von zwei Genen bestimmt wird, die ein leichtes Linkage-Disequilibrium aufweisen.
Wie viele F2-Pflanzen müssen wir aufziehen aund auszählen, um diese Abweichung erkennen zu können?
Grobe Rechnung
Der Standardfehler für die Schätzung des Mittelwerts beträgt für \(n\) F2-Pflanzen \(\sqrt{p(1-p)/n}=0.43/\sqrt{n}\). Ob wir hier in \(p(1-p)\) den Null-Wert 0.25 einsetzen, oder den Alternativwert 0.22, macht kaum einen Unterschied:
sqrt( .25* (1-.25) )
[1] 0.4330127
sqrt( .22* (1-.22) )
[1] 0.4142463
Wir rechnen einfach mit 0.42 weiter.
Um eine Abweichung von 0.25 zu 0.22, also eine Abweichung von 0.03 gut erkennen zu können sollte der Standardfehler deutlich geringer als 0.03 sein. Für welches \(n\) erhalten wir einen Standardfehler von 0.01?
Wir suchen \(n\), so dass \(\sqrt{p(1-p)/n}=0.42/\sqrt{n}=0.01\), und lösen auf: \(n=(0.42/0.01)^2\).
( 0.42/0.01 )^2
[1] 1764
Wir sollten also mindestens 1764 Pflanzen auszählen.
Was wäre, wenn die Abweichung nur 0.245 statt 0.25 gewesen wäre? Wenn wir wieder einen Standardfehler des geschäzten Anteils haben möchten, die kleiner als ein Drittel der Abweichung ist, dann brauchen wir schon über 15000 Pflanzen:
( 0.42/ (0.01/3) )^2
[1] 15876
Wenn wir also Resourcen haben, um z.B. 2000 Pflanzen anzubauen und auszuzählen, können wir vermutlich eine Abweichung um 3 Prozentpunkte gut erkennen. Falls die Abweichung aber nur einen halben Prozentpunkt betragen sollte, hätten wir keine Chance.
Simulation
Um eine genauere Einschätzung zu erhalten, als die einfache Rechnung von eben bieten kann, simulieren wir den ersten Fall, nämlich dass die wahre Wahrscheinlichkeit, eine gelbsamige Pflanze zu erhalten \(p=0.22\) beträgt statt mendelsch \(p_0=0.25\). Wir ziehen \(n=2000\) Pflanzen groß.
set.seed( 13245768 )n <-2000p <-0.22k <-rbinom( 1, n, p )k
[1] 452
Wir führen einen Binomial-Test durch, um zu sehen, ob wir die Nullhypothese mendelscher Segregation mit \(p_0=0.25\) verwerfen dürfen:
p0 <-0.25binom.test( k, n, p0 )
Exact binomial test
data: k and n
number of successes = 452, number of trials = 2000, p-value = 0.01316
alternative hypothesis: true probability of success is not equal to 0.25
95 percent confidence interval:
0.2078324 0.2449743
sample estimates:
probability of success
0.226
Bei diesem p-Wert erschiene es uns unwahrscheinlich, dass die Segregation Mendelsch ist, und wir würden auf eine Abweichung von 25% schließen. Aber vielleicht hatten wir bei dieser Simulation Glück.
Wir wiederholen die Simulation sehr oft (z.B. 3000 mal) und heben jeweils den p-Wert auf:
replicate( 3000, { k <-rbinom( 1, n, p )binom.test( k, n, p0 )$p.value} ) -> p_values
Wie oft lag der p-Wert unter 0.05?
mean( p_values < .05 )
[1] 0.883
Die statistische Power unseres Versuchsplan beträgt also 88%, wenn wir uns von einem p-Wert unter 5% überzeugen lassen.
Mit einer Wahrscheinlichkeit von 88% wir unser Versuch mit 2000 Pflanzen ein Ergebnis mit \(p<0.05\) erzielen – wenn denn unsere Annahme stimmt, dass die Abweichung (mindestens) drei Prozentpunkte beträgt.
Wenn wir hingegen nur einen p-Wert unter 1% für überzeugend halten, ist die Power nur 72%:
mean( p_values < .01 )
[1] 0.7083333
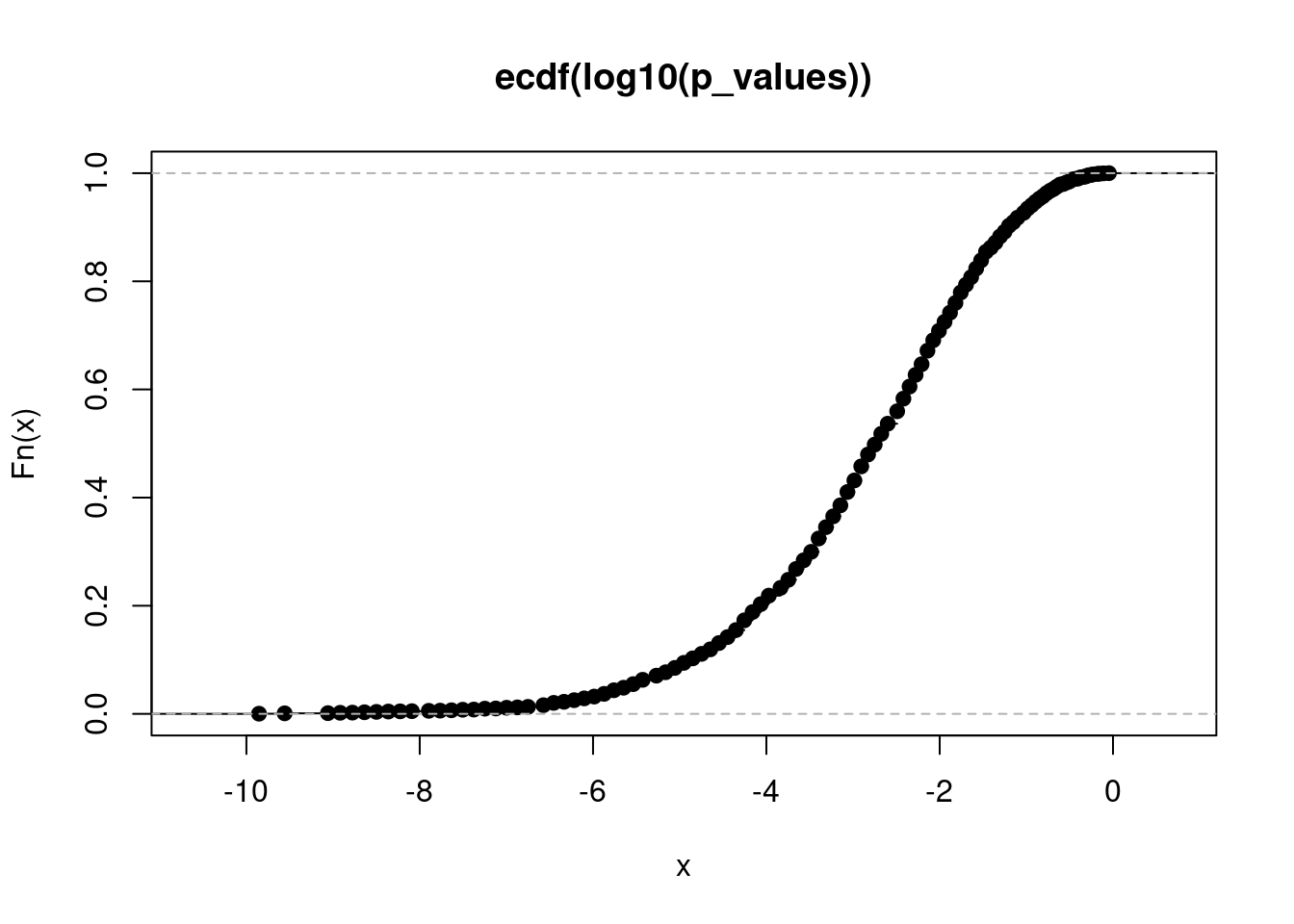
Das folgende Diagramm zeigt eine sog. “empirical cumulative distribution function” (ECDF) für den dekadischen Logarithmus der simulierten p-Werte:
plot( ecdf( log10( p_values ) ) )
Man liest das Diagramm wie folgt:
Wir möchten die Power bestimmten, wenn wir p-Werte unter 0.01 fordern. Der dekadische Logarithmus des p-Werts soll also unter -2 liegen (denn \(\log_{10} .01=-2\)). Bei x=-2 liegt die Kurve bei y=0.71; dies bedeutet: 71% der logarithmierten p-Werte liegen unter -2, bei 71% der Simulationen lag der p-Wert also bei 0.01. Sie können von diesem Diagramm also die Power für verschiedene p-Grenzen ablesen.
Wir könnten das Diagramm erweitern, indem wir mehrere Linien einzeichnen, denen verschiedene Annahmen für die Effektgröße (die Abweichung \(p-p_0\)) oder verschiedene Stichproben-Umfänge \(n\) zugrunde liegen.